|
Free ticket to P99 CONF — 60+ low-latency engineering talks (Sponsored)
 |
P99 CONF is the technical conference for anyone who obsesses over high-performance, low-latency applications. Engineers from Pinterest, Prime Video, Clickhouse, Gemini, Arm, Rivian and VW Group Technology, Meta, Wayfair, Disney, Uber, NVIDIA, and more will be sharing 60+ talks on topics like Rust, Go, Zig, distributed data systems, Kubernetes, and AI/ML.
Join 20K of your peers for an unprecedented opportunity to learn from experts like Chip Huyen (author of the O’Reilly AI Engineering book), Alexey Milovidov (Clickhouse creator/CTO), Andy Pavlo (CMU professor) and more – for free, from anywhere.
Bonus: Registrants are eligible to enter to win 300 free swag packs, get 30-day access to the complete O’Reilly library & learning platform, plus free digital books.
Disclaimer: The details in this post have been derived from the official documentation shared online by the Anthropic Engineering Team. All credit for the technical details goes to the Anthropic Engineering Team. The links to the original articles and sources are present in the references section at the end of the post. We’ve attempted to analyze the details and provide our input about them. If you find any inaccuracies or omissions, please leave a comment, and we will do our best to fix them.
Open-ended research tasks are difficult to handle because they rarely follow a predictable path. Each discovery can shift the direction of inquiry, making it impossible to rely on a fixed pipeline. This is where multi-agent systems become important
By running several agents in parallel, multi-agent systems allow breadth-first exploration, compress large search spaces into manageable insights, and reduce the risk of missing key information.
Anthropic’s engineering team also found that this approach delivers major performance gains. In internal evaluations, a system with Claude Opus 4 as the lead agent and Claude Sonnet 4 as supporting subagents outperformed a single-agent setup by more than 90 percent. The improvement was strongly linked to token usage and the ability to spread reasoning across multiple independent context windows, with subagents enabling the kind of scaling that a single agent cannot achieve.
However, the benefits also come with costs:
Multi-agent systems consume approximately fifteen times more tokens than standard chat interactions, making them best suited for tasks where the value of the outcome outweighs the expense.
They excel at problems that can be divided into parallel strands of research, but are less effective for tightly interdependent tasks such as coding.
Despite these trade-offs, multi-agent systems are proving to be a powerful way to tackle complex, breadth-heavy research challenges. In this article, we will understand the architecture of the multi-agent research system that Anthropic built.
 |
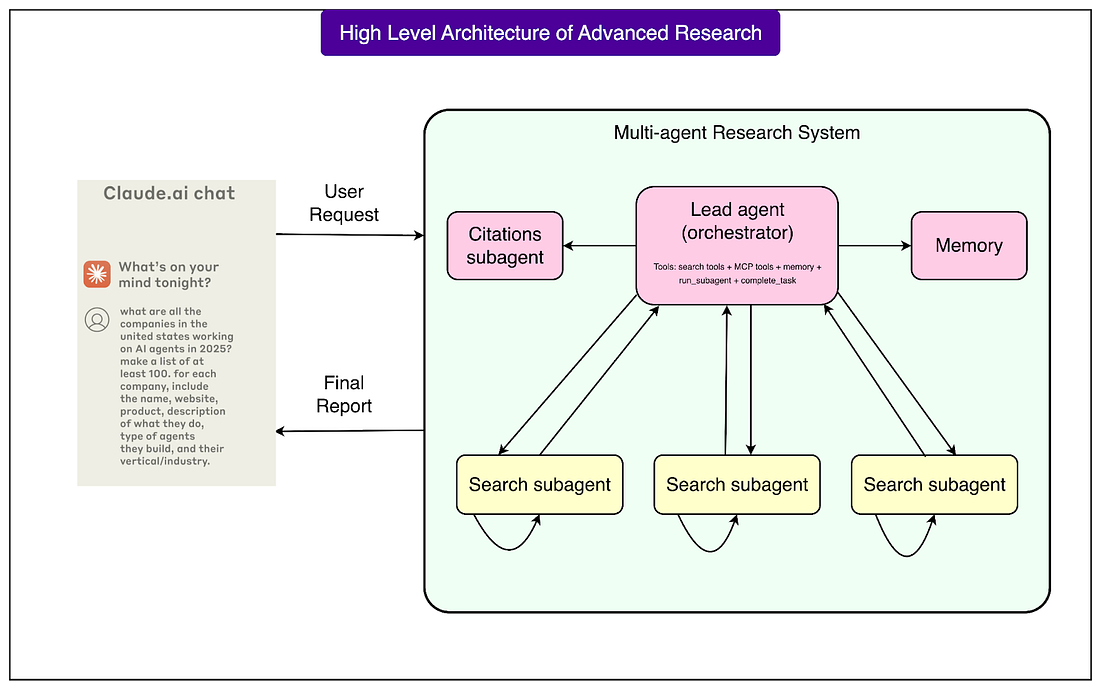
The Architecture of the Research System
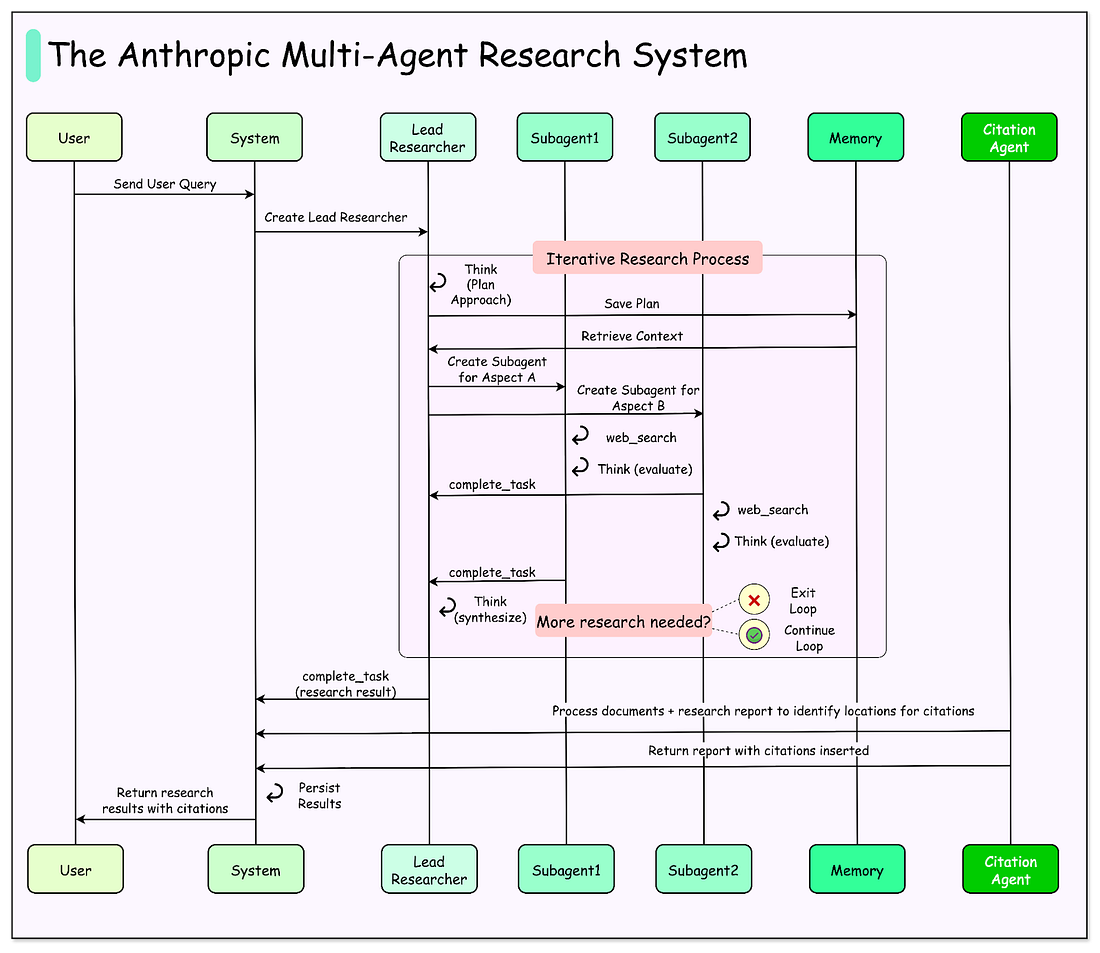
The research system is built on an orchestrator-worker pattern, a common design in computing where one central unit directs the process and supporting units carry out specific tasks.
In this case, the orchestrator is the Lead Researcher agent, while the supporting units are subagents that handle individual parts of the job. Here are the details about the same:
Lead Researcher agent: This is the main coordinator. When a user submits a query, the Lead Researcher analyzes it, decides on an overall strategy, and records the plan in memory. Memory management is important here because large research tasks can easily exceed the token limit of the model’s context window. By saving the plan, the system avoids losing track when tokens run out.
Subagents: These are specialized agents created by the Lead Researcher. Each subagent is given a specific task, such as exploring a certain company, checking a particular time period, or looking into a technical detail. Because subagents operate in parallel and maintain their own context, they can search, evaluate results, and refine queries independently without interfering with one another. This separation of tasks reduces duplication and makes the process more efficient.
Citation Agent: Once enough information has been gathered, the results are passed to a Citation Agent. Its job is to check every claim against the sources, match citations correctly, and ensure the final output is traceable. This prevents errors such as making statements without evidence or attributing information to the wrong source.
See the diagram below that shows the high level architecture of these components:
 |
This design differs from traditional Retrieval-Augmented Generation (RAG) systems.
In standard RAG, the model retrieves a fixed set of documents that look most similar to the query and then generates an answer from them. The limitation is that retrieval happens only once, in a static way.
The multi-agent system operates dynamically: it performs multiple rounds of searching, adapts based on the findings, and explores deeper leads as needed. In other words, it learns and adjusts during the research process rather than relying on a single snapshot of data.
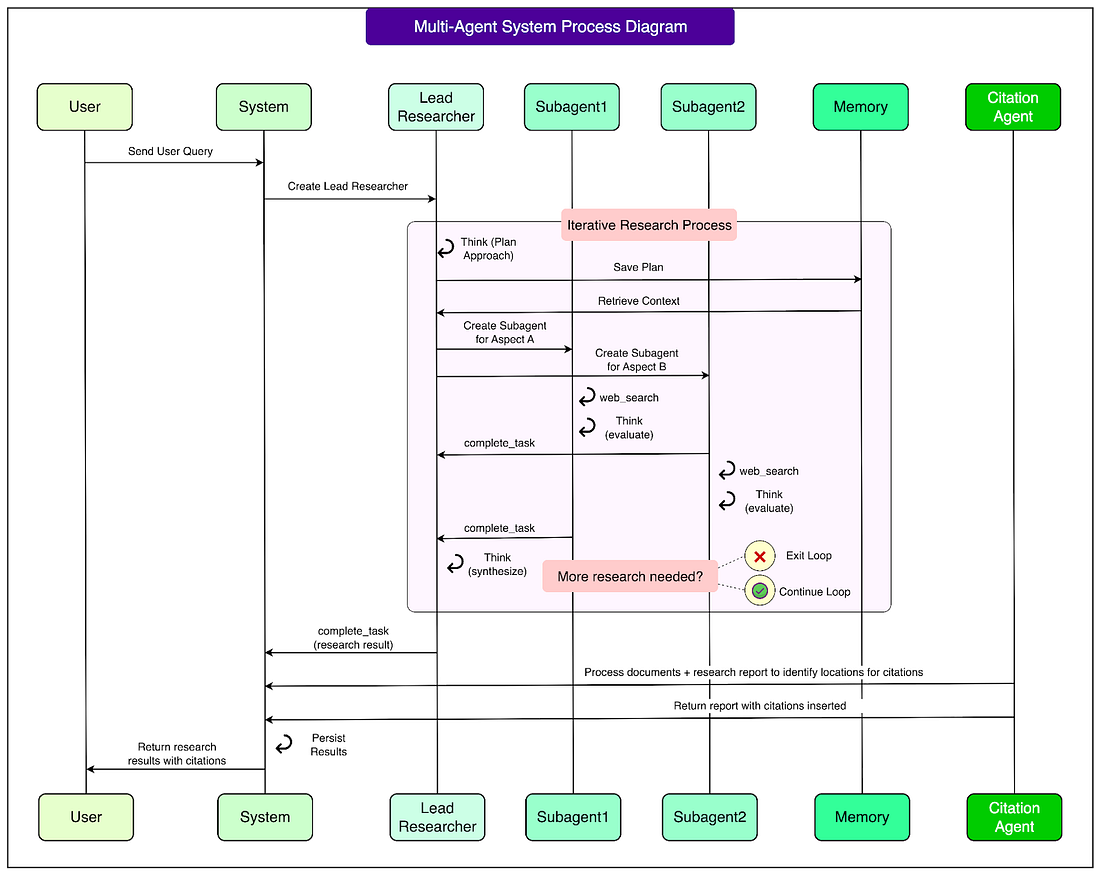
The complete workflow looks like this:
A user submits a query.
The Lead Researcher creates a plan for performing the investigation.
Subagents are spawned, each carrying out searches or using tools in parallel.
The Lead Researcher gathers their results, synthesizes them, and decides if further work is required. If so, more subagents can be created, or the strategy can be refined.
Once enough information is collected, everything is handed to the Citation Agent, which ensures the report is properly sourced.
The final research report is then returned to the user.
See the diagram below for more details:
 |