|
The 2025 Data Streaming & AI Report (Sponsored)
 |
AI is only as powerful as the data behind it — but most teams aren’t ready.
We surveyed 200 senior IT and data leaders to uncover how enterprises are really using streaming to power AI, and where the biggest gaps still exist.
Discover the biggest challenges in real-time data infrastructure, the top obstacles slowing down AI adoption, and what high-performing teams are doing differently in 2025.
Download the full report to see where your organisation stands.
Disclaimer: The details in this post have been derived from the details shared online by the Zalando Engineering Team. All credit for the technical details goes to the Zalando Engineering Team. The links to the original articles and sources are present in the references section at the end of the post. We’ve attempted to analyze the details and provide our input about them. If you find any inaccuracies or omissions, please leave a comment, and we will do our best to fix them.
Zalando is one of Europe’s largest fashion and lifestyle platforms, connecting thousands of brands, retailers, and physical stores under one digital ecosystem.
As the company’s scale grew, so did the volume of commercial data it generated. This included information about product performance, sales patterns, pricing insights, and much more. This data was not just important for Zalando itself but also for its vast network of retail partners who relied on it to make critical business decisions.
However, sharing this data efficiently with external partners became increasingly complex.
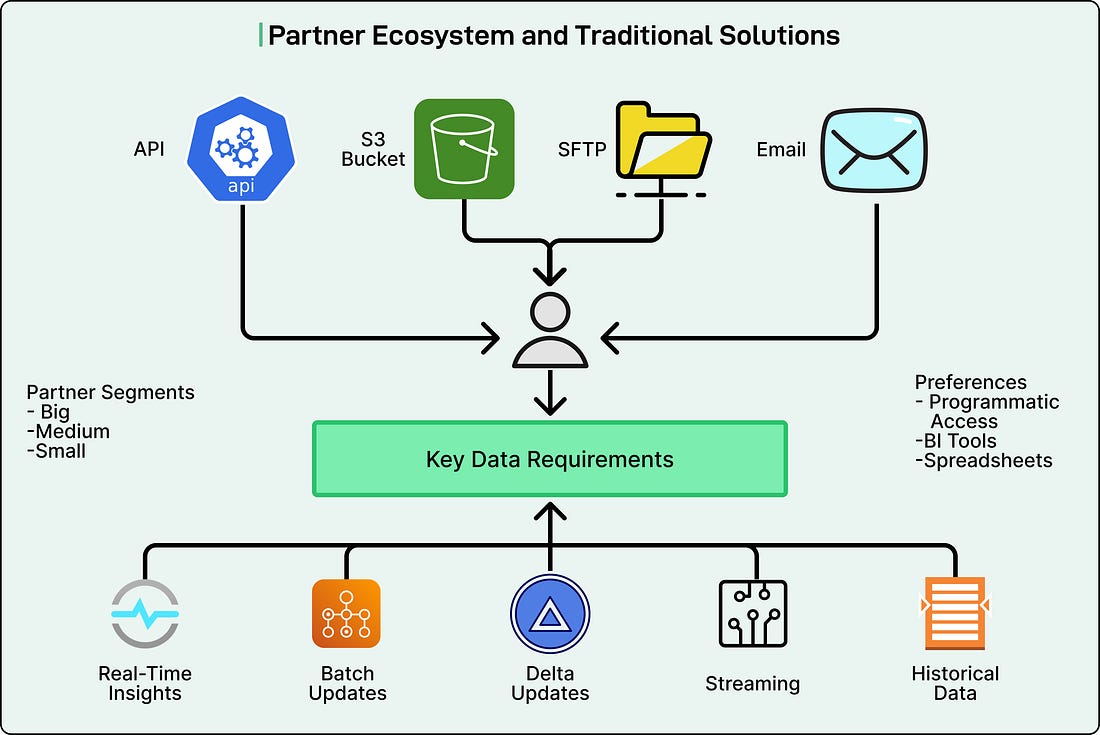
Zalando’s Partner Tech division, responsible for data sharing and collaboration with partners, found itself managing a fragmented and inefficient process. Partners needed clear visibility into how their products were performing on the platform, but accessing that information was far from seamless. Data was scattered across multiple systems and shared through a patchwork of methods. Some partners received CSV files over SFTP, others pulled data via APIs, and many depended on self-service dashboards to manually export reports. Each method served a purpose, but together created a tangled system where consistency and reliability were hard to maintain. Many partners had to dedicate the equivalent of 1.5 full-time employees each month just to extract, clean, and consolidate the data they received. Instead of focusing on strategic analysis or market planning, skilled analysts spent valuable time performing repetitive manual work.
There was also a serious accessibility issue. The existing interfaces were not designed for heavy or large-scale data downloads. Historical data was often unavailable when partners needed it most, such as during key planning or forecasting cycles. As a result, even well-resourced partners struggled to build an accurate picture of their own performance.
This problem highlighted a critical gap in Zalando’s data strategy. Partners did not just want raw data or operational feeds. They wanted analytical-ready datasets that could be accessed programmatically and integrated directly into their internal analytics tools. In simple terms, they needed clean, governed, and easily retrievable data that fit naturally into their business workflows.
To address this challenge, the Zalando Engineering Team began a multi-year journey to rebuild its partner data sharing framework from the ground up. The result of this effort was Zalando’s adoption of Delta Sharing, an open protocol for secure data sharing across organizations. In this article, we will look at how Zalando built such a system and the challenges they faced.
Zalando’s Partner Ecosystem
To solve the problem of fragmented data sharing, the Zalando Engineering Team first needed to understand who their partners were and how they worked with data.
 |
Zalando operates through three major business models:
Wholesale: Zalando purchases products from brands and resells them directly on its platform.
Partner Program: Brands list and sell products directly to consumers through Zalando’s marketplace.
Connected Retail: Physical retail stores connect their local inventory to an online platform, allowing customers to buy nearby and pick up in person.
Each of these models generates unique datasets, and the scale of those datasets varies dramatically. A small retailer may only deal with a few hundred products and generate a few megabytes of data each week. In contrast, a global brand might handle tens of thousands of products and need access to hundreds of terabytes of historical sales data for planning and forecasting.
In total, Zalando manages more than 200 datasets that support a business generating over €5 billion in gross merchandise value (GMV). These datasets are critical to helping partners analyze trends, adjust pricing strategies, manage inventory, and plan promotions. However, not all partners have the same level of technical sophistication or infrastructure to consume this data effectively.
Zalando’s partners generally fall into three categories based on their data maturity. See the table below:
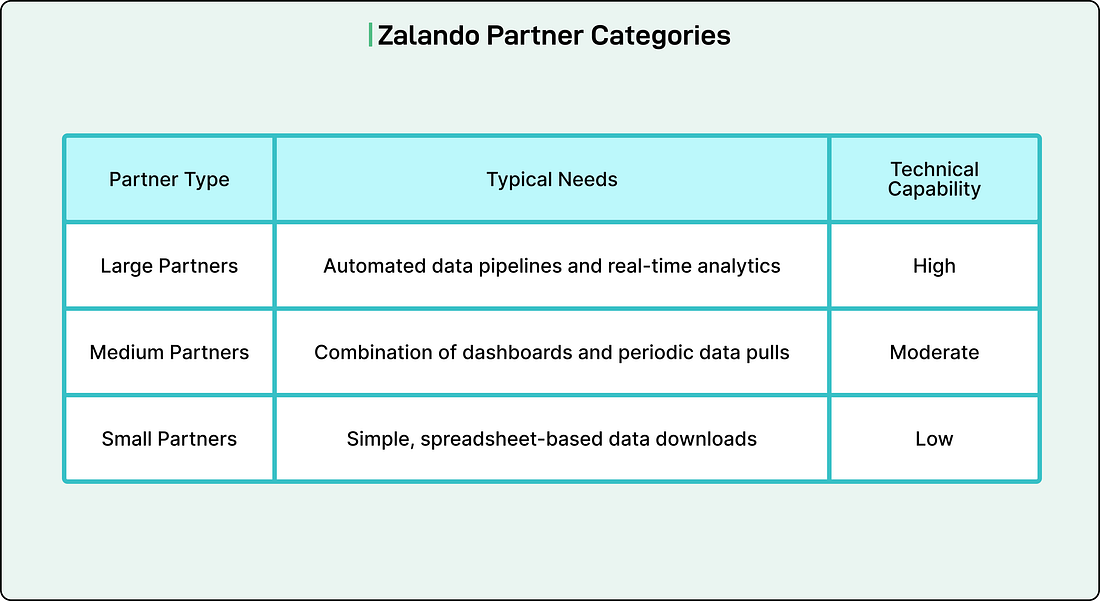 |
Large enterprise partners often have their own analytics teams, data engineers, and infrastructure. They expect secure, automated access to data that integrates directly into their internal systems. Medium-sized partners prefer flexible solutions that combine manual and automated options, such as regularly updated reports and dashboards. Smaller partners value simplicity above all else, often relying on spreadsheet-based workflows and direct downloads.
Zalando’s existing mix of data-sharing methods (such as APIs, S3 buckets, email transfers, and SFTP connections) worked in isolation but could not scale to meet all these varied needs consistently.
Solution Criteria and Evaluation
After understanding the different needs of its partner ecosystem, the Zalando Engineering Team began to look for a better, long-term solution. The goal was not only to make data sharing faster but also to make it more reliable, scalable, and secure for every partner, from small retailers to global brands.
The team realized that fixing the problem required more than improving existing systems. They needed to design an entirely new framework that could handle massive datasets, provide real-time access, and adapt to each partner’s technical capability without creating new complexity. To do that, Zalando created a clear list of evaluation criteria that would guide their decision.