|
Latest articles
If you’re not a subscriber, here’s what you missed this month.
 |
To receive all the full articles and support ByteByteGo, consider subscribing:
Every modern application needs to handle transactions. These are operations that must either succeed completely or fail.
In a monolithic system, this process is usually straightforward. The application talks to a single database, and all the data needed for a business operation lives in one place. Developers can use built-in database transactions or frameworks that automatically manage them to ensure that the system remains consistent even when something goes wrong.
For example, when you make an online payment, the application might deduct money from your account and record the transaction in a ledger. Both actions happen within a single database transaction. If one action fails, the database automatically rolls everything back so that no partial updates are left behind. This behavior is part of the ACID properties (Atomicity, Consistency, Isolation, and Durability) that guarantee reliable and predictable outcomes.
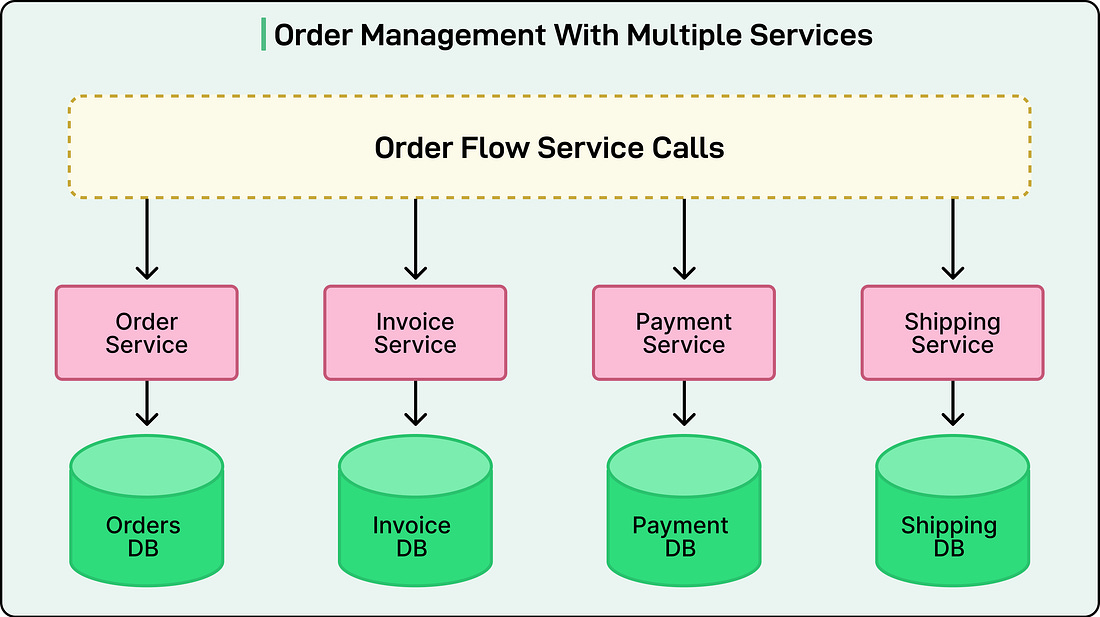
However, as systems evolve and grow larger, many organizations adopt a services-based or microservices architecture. In such architectures, a business process often involves multiple services, each managing its own database. For instance, an e-commerce system might have separate services for orders, payments, shipping, and inventory. Each of these services owns its own data store and operates independently.
Now imagine a business transaction that spans all these services. Placing an order might require updating the order database, reserving stock in the inventory database, and recording payment details in another database. If one of these steps fails, the system must find a way to keep all services consistent. This is where the problem begins.
See the diagram below:
 |
This challenge is known as the problem of distributed transactions. Traditional techniques like two-phase commit (2PC) attempt to coordinate commits across multiple databases, but they can reduce performance, limit availability, and add significant complexity. As applications become more distributed and use different types of databases or message brokers, these traditional methods become less practical.
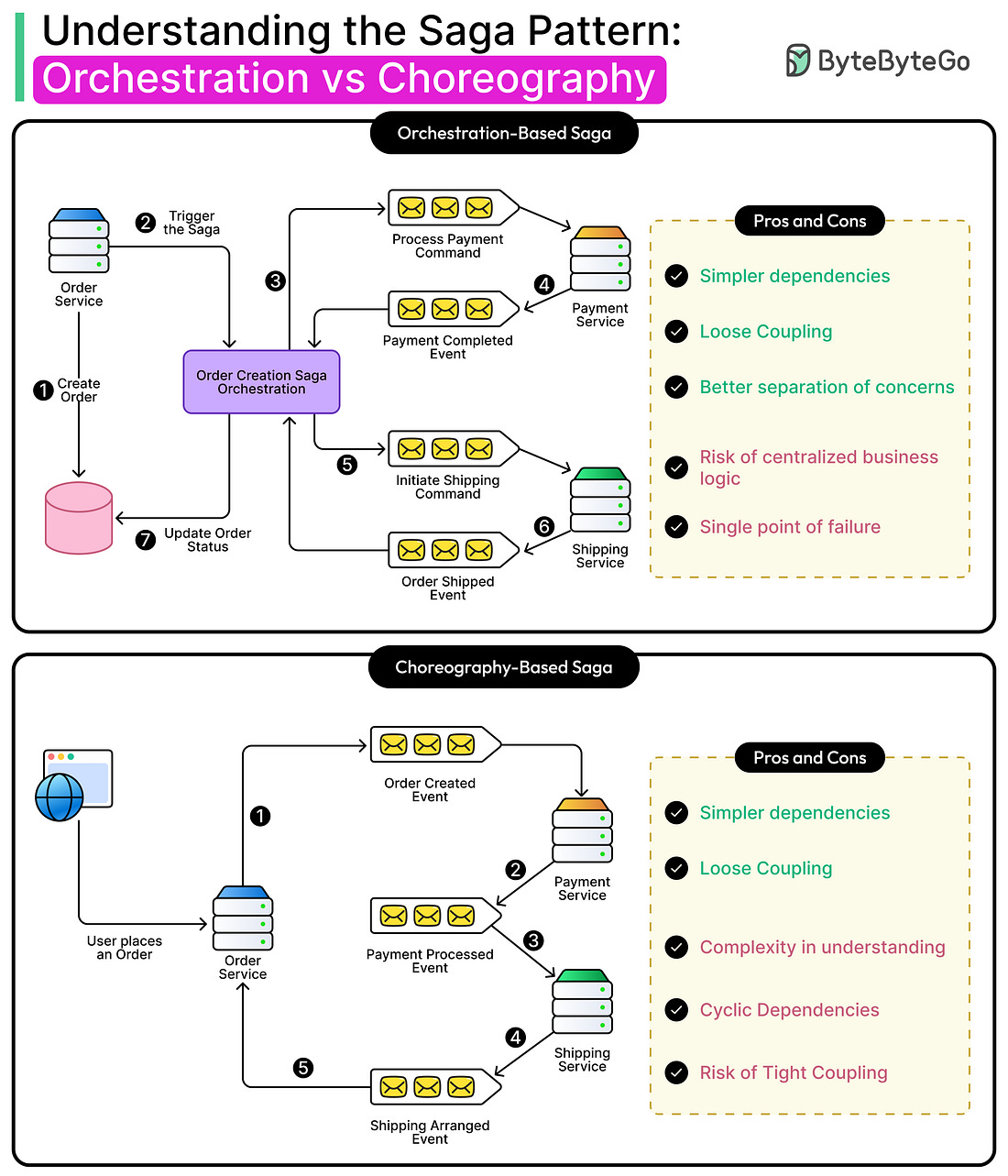
To overcome these limitations, modern architectures rely on alternative patterns that provide consistency without strict coupling or blocking behavior. One of the most effective of these is the Saga pattern.
In this article, we will look at how the Saga pattern works and the pros and cons of various approaches to implement this pattern.
 |