|
Cut Code Review Time & Bugs in Half (Sponsored)
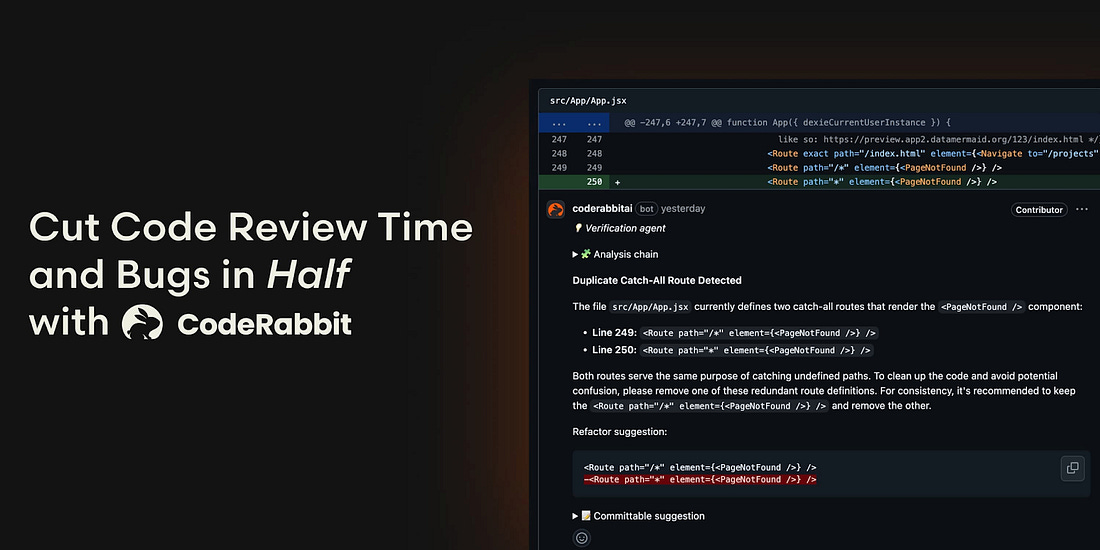 |
Code reviews are critical but time-consuming. CodeRabbit acts as your AI co-pilot, providing instant Code review comments and potential impacts of every pull request.
Beyond just flagging issues, CodeRabbit provides one-click fix suggestions and lets you define custom code quality rules using AST Grep patterns, catching subtle issues that traditional static analysis tools might miss.
CodeRabbit has so far reviewed more than 10 million PRs, installed on 2 million repositories, and used by 100 thousand Open-source projects. CodeRabbit is free for all open-source repo’s.
Disclaimer: The details in this post have been derived from the details shared online by the Meta Engineering Team. All credit for the technical details goes to the Meta Engineering Team. The links to the original articles and sources are present in the references section at the end of the post. We’ve attempted to analyze the details and provide our input about them. If you find any inaccuracies or omissions, please leave a comment, and we will do our best to fix them.
When Meta announced in Q2 2025 that its new Generative Ads Model (GEM) had driven a 5% increase in ad conversions on Instagram and a 3% increase on Facebook Feed, the numbers might have seemed modest.
However, at Meta’s scale, these percentages translate to billions of dollars in additional revenue and represent a fundamental shift in how AI-powered advertising works.
GEM is the largest foundation model ever built for recommendation systems. It has been trained at the scale typically reserved for large language models like GPT-4 or Claude. Yet here’s the paradox: GEM is so powerful and computationally intensive that Meta can’t actually use it directly to serve ads to users.
Instead, the company developed a teacher-student architecture that lets smaller, faster models benefit from GEM’s intelligence without inheriting its computational cost.
In this article, we look at how the Meta engineering team built GEM and the challenges they overcame.
👋 Goodbye low test coverage and slow QA cycles (Sponsored)
 |
Bugs sneak out when less than 80% of user flows are tested before shipping. However, getting that kind of coverage (and staying there) is hard and pricey for any team.
QA Wolf’s AI-native solution provides high-volume, high-speed test coverage for web and mobile apps, reducing your organization’s QA cycle to minutes.
They can get you:
80% automated E2E test coverage in weeks—not years
Unlimited parallel test runs
24-hour maintenance and on-demand test creation
Zero flakes, guaranteed
The benefit? No more manual E2E testing. No more slow QA cycles. No more bugs reaching production.
With QA Wolf, Drata’s team of engineers achieved 4x more test cases and 86% faster QA cycles.
⭐ Rated 4.8/5 on G2
The Core Problem GEM Solves
Every day, billions of users scroll through Facebook, Instagram, and other Meta platforms, generating trillions of potential ad impression opportunities. Each impression represents a decision point: which ad, from millions of possibilities, should be shown to this specific user at this particular moment? Getting this wrong means wasting advertiser budgets on irrelevant ads and annoying users with content they don’t care about. Getting it right creates value for everyone involved.
Traditional ad recommendation systems struggled with this in several ways. Some systems treated each platform separately, which meant that insights about user behavior on Instagram couldn’t inform predictions on Facebook. This siloed approach missed valuable cross-platform patterns. Other systems tried to treat all platforms identically, ignoring the fact that people interact with Instagram Stories very differently from how they browse Facebook Feed. Neither approach was optimal.
The data complexity also compounds these challenges in the following ways:
Meaningful signals like clicks and conversions are extremely sparse compared to total impression volume.
User features are dynamic and constantly changing.
The system must process multimodal inputs, including text, images, video, and complex behavioral sequences.
Traditional models had severe memory limitations, typically only considering a user’s last 10 to 20 actions.
GEM’s goal was to create a unified intelligence that understands users holistically across Meta’s entire ecosystem, learning from long behavioral histories and complex cross-platform patterns while maintaining the nuance needed to optimize for each specific surface and objective.
How GEM Understands Users?
GEM’s architecture processes user and ad information through three complementary systems, each handling a different aspect of the prediction problem.