|
Yesterday’s data can’t answer today’s questions. (Sponsored)
 |
Static training data can’t keep up with fast-changing information, leaving your models to guess. We recommend this technical guide from You.com, which gives developers the code and framework to connect GenAI apps to the live web for accurate, real-time insights.
What you’ll get:
A step-by-step Python tutorial to integrate real-time search with a single GET request
The exact code logic to build a “Real-Time Market Intelligence Agent” that automates daily briefings
Best practices for optimizing latency, ensuring zero data retention, and establishing traceability
Turn “outdated” into “real-time.”
For a long time, AI systems were specialists confined to a single sense. For example:
Computer vision models could identify objects in photographs, but couldn’t describe what they saw.
Natural language processing systems could write eloquent prose but remained blind to images.
Audio processing models could transcribe speech, but had no visual context.
This fragmentation represented a fundamental departure from how humans experience the world. Human cognition is inherently multimodal. We don’t just read text or just see images. We simultaneously observe facial expressions while listening to the tone of voice. We connect the visual shape of a dog with the sound of a bark and the written word “dog.”
To create AI that truly operates in the real world, these separated sensory channels needed to converge.
Multimodal Large Language Models represent this convergence. For example, GPT-4o can respond to voice input in just 232 milliseconds, matching human conversation speed. Google’s Gemini can process an entire hour of video in a single prompt.
These capabilities emerge from a single unified neural network that can see, hear, and read simultaneously.
But how does a single AI system understand such fundamentally different types of data? In this article, we try to answer this question.
Cut Complexity and Drive Growth with Automation (Sponsored)
 |
What if you could spend most of your IT resources on innovation, not maintenance?
The latest report from the IBM Institute for Business Value explores how businesses are using intelligent automation to get more out of their technology, drive growth & cost the cost of complexity.
A Shared Mathematical Language
The core breakthrough behind multimodal LLMs is quite simple. Every type of input, whether text, images, or audio, gets converted into the same type of mathematical representation called embedding vectors. Just as human brains convert light photons, sound waves, and written symbols into uniform neural signals, multimodal LLMs convert diverse data types into vectors that occupy the same mathematical space.
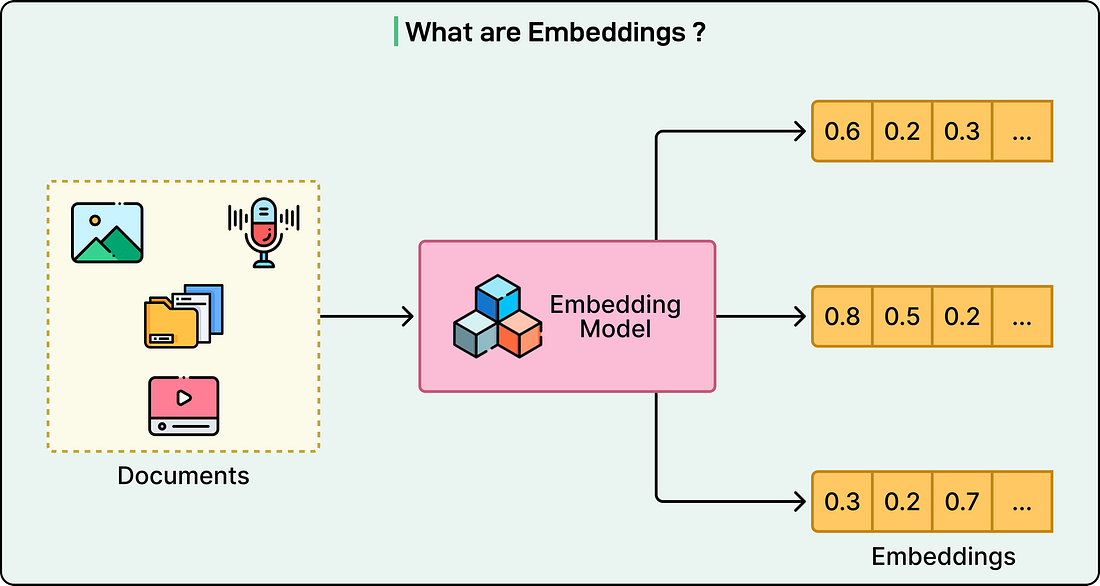 |
Let us consider a concrete example. A photograph of a dog, the spoken word “dog,” and the written text “dog” all get transformed into points in a high-dimensional mathematical space. These points cluster together, close to each other, because they represent the same concept.
This unified representation enables what researchers call cross-modal reasoning. The model can understand that a barking sound, a photo of a golden retriever, and the sentence “the dog is happy” all relate to the same underlying concept. The model doesn’t need separate systems for each modality. Instead, it processes everything through a single architecture that treats visual patches and audio segments just like text tokens.