|
How to stop bots from abusing free trials (Sponsored)
 |
Free trials help AI apps grow, but bots and fake accounts exploit them. They steal tokens, burn compute, and disrupt real users.
Cursor, the fast-growing AI code assistant, uses WorkOS Radar to detect and stop abuse in real time. With device fingerprinting and behavioral signals, Radar blocks fraud before it reaches your app.
You open an app with one specific question in mind, but the answer is usually hidden in a sea of reviews, photos, and structured facts. Modern content platforms are information-rich, though surfacing direct answers can still be a challenge. A good example is Yelp business pages. Imagine you are deciding where to go and you ask “Is the patio heated?”. The page might contain the answer in a couple of reviews, a photo caption, or an attribute field, but you still have to scan multiple sections to piece it together.
A common way to solve this is to integrate an AI assistant inside the app. The assistant retrieves the right evidence and turns it into a single direct answer with citations to the supporting snippets.
 |
This article walks through what it takes to ship a production-ready AI assistant using Yelp Assistant on business pages as a concrete case study. We’ll cover the engineering challenges, architectural trade-offs, and practical lessons from the development of the Yelp Assistant.
Note: This article is written in collaboration with Yelp. Special thanks to the Yelp team for sharing details with us about their work and for reviewing the final article before publication.
High-Level System Design
To deliver answers that are both accurate and cited, we cannot rely on an LLM’s internal knowledge alone. Instead, we use Retrieval-Augmented Generation (RAG).
RAG decouples the problem into two distinct phases: retrieval and generation, supported by an offline indexing pipeline that prepares the knowledge store.
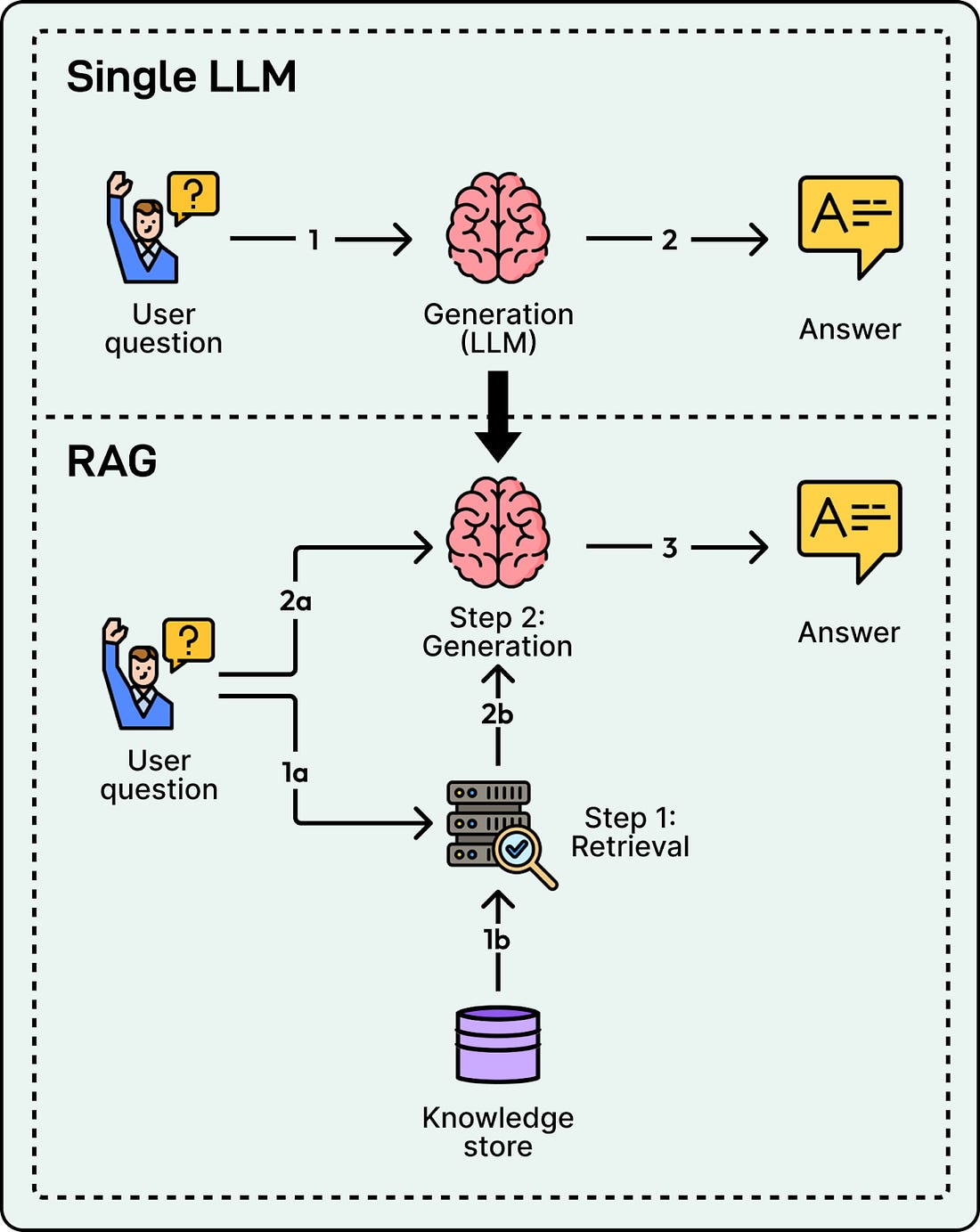 |
The development of a RAG system starts with an indexing pipeline, which builds a knowledge store from raw data offline. Upon receiving a user query, the retrieval system scans this store using both lexical search for keywords and semantic search for intent to locate the most relevant snippets. Finally, the generation phase feeds these snippets to the LLM with strict instructions to answer solely based on the provided evidence and to cite specific sources.
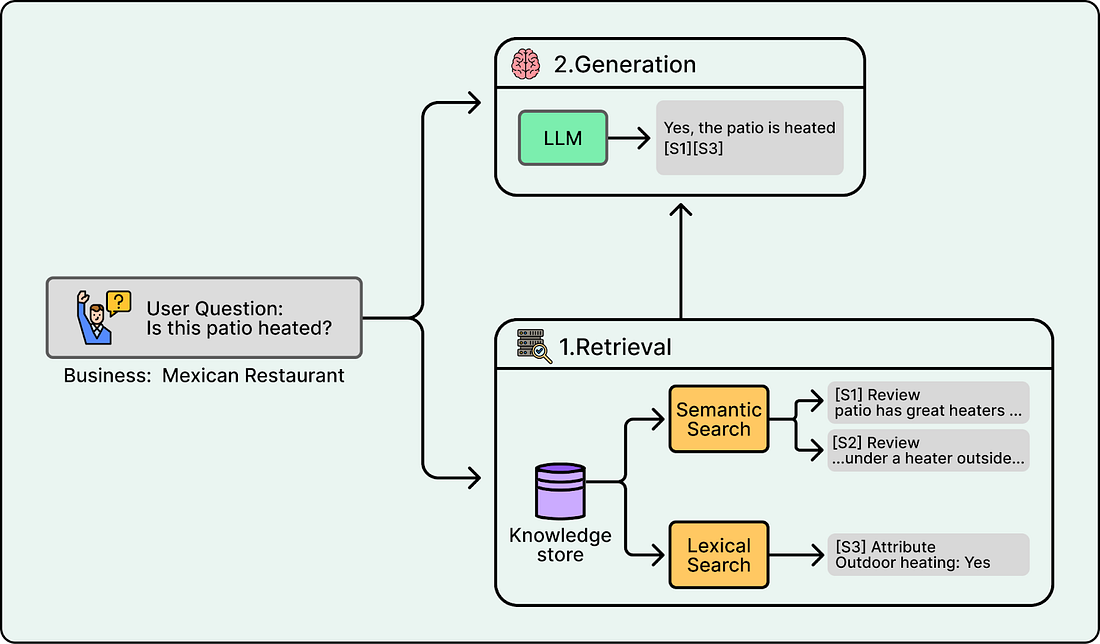 |
Citations are typically produced by having the model output citation markers that refer to specific snippets. For example, if the prompt includes snippets with IDs S1, S2, and S3, the model might generate “Yes, the patio is heated” and attach markers like [S1] and [S3]. A citation resolution step then maps those markers back to the original sources, such as a specific review excerpt, photo caption, or attribute field, and formats them for the UI. Finally, citations are verified to ensure every emitted citation maps to real retrievable content.
 |
While this system is enough for a prototype, a production system requires additional layers for reliability, safety, and performance. The rest of this article uses the Yelp Assistant as a case study to explore the real-world engineering challenges of building this at scale and the mitigations to solve them.