|
Your free ticket to Monster SCALE Summit is waiting — 50+ engineering talks on data-intensive applications (Sponsored)
 |
Monster SCALE Summit is a virtual conference all about extreme-scale engineering and data-intensive applications. Engineers from Discord, Disney, LinkedIn, Uber, Pinterest, Rivian, ClickHouse, Redis, MongoDB, ScyllaDB + more will be sharing 50+ talks on topics like:
Distributed databases
Streaming and real-time processing
Intriguing system designs
Approaches to a massive scaling challenge
Methods for balancing latency/concurrency/throughput
Infrastructure built for unprecedented demands.
Don’t miss this chance to connect with 20K of your peers designing, implementing, and optimizing data-intensive applications – for free, from anywhere.
LinkedIn serves hundreds of millions of members worldwide, delivering fast experiences whether someone is loading their feed or sending a message. Behind the scenes, this seamless experience depends on thousands of software services working together. Service Discovery is the infrastructure system that makes this coordination possible.
Consider a modern application at scale. Instead of building one massive program, LinkedIn breaks functionality into tens of thousands of microservices. Each microservice handles a specific task like authentication, messaging, or feed generation. These services need to communicate with each other constantly, and they need to know where to find each other.
Service discovery solves this location problem. Instead of hardcoding addresses that can change as servers restart or scale, services use a directory that tracks where every service currently lives. This directory maintains IP addresses and port numbers for all active service instances.
At LinkedIn’s scale, with tens of thousands of microservices running across global data centers and handling billions of requests each day, service discovery becomes exceptionally challenging. The system must update in real time as servers scale up or down, remain highly reliable, and respond within milliseconds.
In this article, we learn how LinkedIn built and rolled out Next-Gen Service Discovery, a scalable control plane supporting app containers in multiple programming languages.
Disclaimer: This post is based on publicly shared details from the LinkedIn Engineering Team. Please comment if you notice any inaccuracies.
Zookeeper-Based Architecture
For the past decade, LinkedIn used Apache Zookeeper as the control plane for service discovery. Zookeeper is a coordination service that maintains a centralized registry of services.
In this architecture, Zookeeper allows server applications to register their endpoint addresses in a custom format called D2, which stands for Dynamic Discovery. The system stored the configuration about how RPC traffic should flow as D2 configs and served them to application clients. The application servers and clients formed the data plane, handling actual inbound and outbound RPC traffic using LinkedIn’s Rest.li framework, a RESTful communication system.
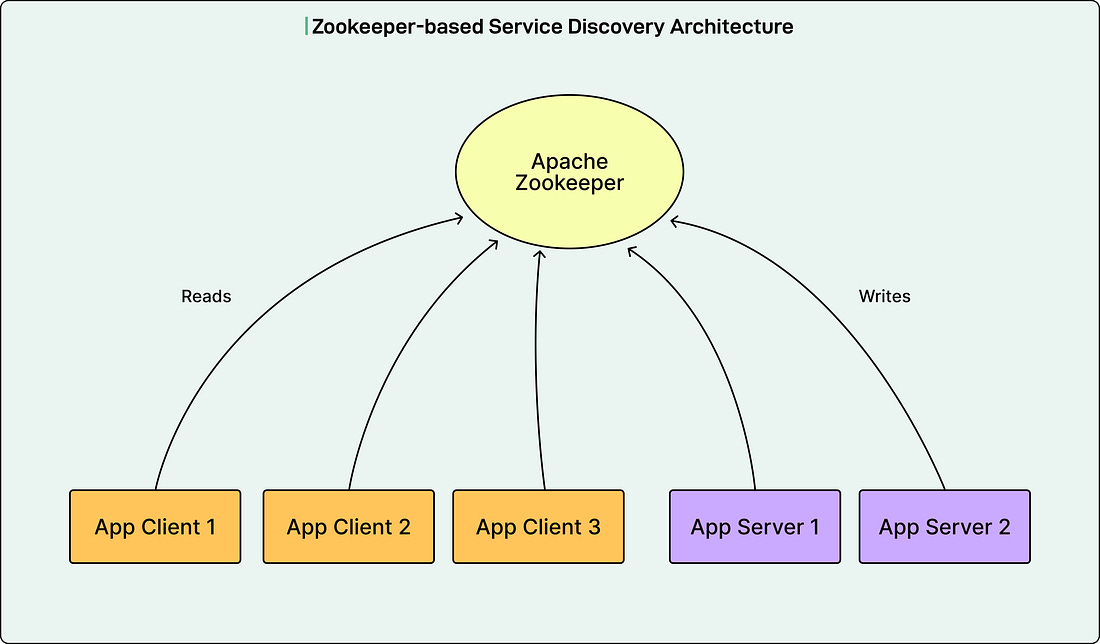 |
Here is how the system worked:
The Zookeeper client library ran on all application servers and clients.
The Zookeeper ensemble took direct write requests from application servers to register their endpoint addresses as ephemeral nodes called D2 URIs.
Ephemeral nodes are temporary entries that exist only while the connection remains active.
The Zookeeper performed health checks on these connections to keep the ephemeral nodes alive.
The Zookeeper also took direct read requests from application clients to set watchers on the server clusters they needed to call. When updates happened, clients would read the changed ephemeral nodes.
Despite its simplicity, this architecture had critical problems in three areas: scalability, compatibility, and extensibility. Benchmark tests conducted in the past projected that the system would reach capacity in early 2025.
Web Search API for your AI applications (Sponsored)
 |
LLMs are powerful—but without fresh, reliable information, they hallucinate, miss context, and go out of date fast. SerpApi gives your AI applications clean, structured web data from major search engines and marketplaces, so your agents can research, verify, and answer with confidence.
Access real-time data with a simple API.