|
Sentry’s AI debugger fixes code wherever it breaks (Sponsored)
 |
🤖Most AI coding tools only see your source code. Seer, Sentry’s AI debugging agent, uses everything Sentry knows about how your code has behaved in production to debug locally, in your PR, and in production.
🛠️How it works:
Seer scans & analyzes issues using all Sentry’s available context.
In development, Seer debugs alongside you as you build
In review, Seer alerts you to bugs that are likely to break production, not nits
In production, Seer can find a bug’s root cause, suggest a fix, open a PR automatically, or send the fix to your preferred IDE.
OpenAI scaled PostgreSQL to handle millions of queries per second for 800 million ChatGPT users. They did it with just a single primary writer supported by read replicas.
At first glance, this should sound impossible. The common wisdom suggests that beyond a certain scale, you must shard the database or risk failure. The conventional playbook recommends embracing the complexity of splitting the data across multiple independent databases.
OpenAI’s engineering team chose a different path. They decided to see just how far they could push PostgreSQL.
Over the past year, their database load grew by more than 10X. They experienced the familiar pattern of database-related incidents: cache layer failures causing sudden read spikes, expensive queries consuming CPU, and write storms from new features. Yet through systematic optimization across every layer of their stack, they achieved five-nines availability with low double-digit millisecond latency. But the road wasn’t easy.
In this article, we will look at the challenges OpenAI faced while scaling Postgres and how the team handled the various scenarios.
Disclaimer: This post is based on publicly shared details from the OpenAI Engineering Team. Please comment if you notice any inaccuracies.
Understanding Single-Primary Architecture
A single-primary architecture means one database instance handles all writes, while multiple read replicas handle read queries.
See the diagram below:
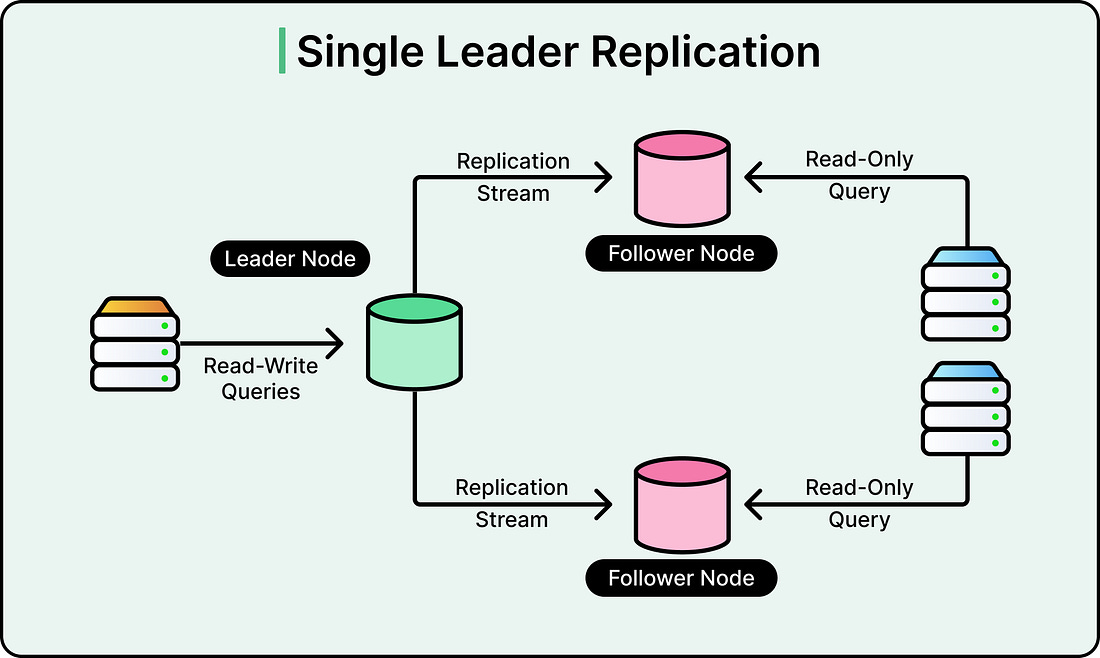 |
This design creates an inherent bottleneck because writes cannot be distributed. However, for read-heavy workloads like ChatGPT, where users primarily fetch data rather than modify it, this architecture can scale effectively if properly optimized.
OpenAI avoided sharding its PostgreSQL deployment for pragmatic reasons. Sharding would require modifying hundreds of application endpoints and could take months or years to complete. Since their workload is primarily read-heavy and current optimizations provide sufficient capacity, sharding remains a future consideration rather than an immediate necessity.
So how did OpenAI go about scaling the read replicas? There were three main pillars to their overall strategy:
Pillar 1: Minimizing Primary Database Load
The primary database represents the system’s most critical bottleneck. OpenAI implemented multiple strategies to reduce pressure on this single writer:
Offloading Read Traffic: OpenAI routes most read queries to replicas rather than the primary. However, some read queries must remain on the primary because they occur within write transactions. For these queries, the team ensures maximum efficiency to avoid slow operations that could cascade into broader system failures.
Migrating Write-Heavy Workloads: The team migrated workloads that could be horizontally partitioned to sharded systems like Azure Cosmos DB. These shardable workloads can be split across multiple databases without complex coordination. Workloads that are harder to shard continue to use PostgreSQL but are being gradually migrated.
Application-Level Write Optimization: OpenAI fixed application bugs that caused redundant database writes. They implemented lazy writes where appropriate to smooth traffic spikes rather than hitting the database with sudden bursts. When backfilling table fields, they enforce strict rate limits even though the process can take over a week. This patience prevents write spikes that could impact production stability.
Pillar 2: Query and Connection Optimization
First, OpenAI identified several expensive queries that consumed disproportionate CPU resources. One particularly problematic query joined 12 tables, and spikes in this query’s volume caused multiple high-severity incidents.
The team learned to avoid complex multi-table joins in their OLTP system. When joins are necessary, OpenAI breaks down complex queries and moves join logic to the application layer, where it can be distributed across multiple application servers.
Object-Relational Mapping frameworks, commonly known as ORMs, generate SQL automatically from code objects. While convenient for developers, ORMs can produce inefficient queries. OpenAI carefully reviews all ORM-generated SQL to ensure it performs as expected. They also configure timeouts like idle_in_transaction_session_timeout to prevent long-running idle queries from blocking autovacuum (PostgreSQL’s cleanup process).
Second, Azure PostgreSQL instances have a maximum connection limit of 5,000. OpenAI previously experienced incidents where connection storms exhausted all available connections, bringing down the service.
Connection pooling solves this problem by reusing database connections rather than creating new ones for each request. Think of it as carpooling. Instead of everyone driving their own car to work, people share vehicles to reduce traffic congestion.
OpenAI deployed PgBouncer as a proxy layer between applications and databases. PgBouncer runs in statement or transaction pooling mode, efficiently reusing connections and reducing the number of active client connections. In benchmarks, average connection time dropped from 50 milliseconds to just 5 milliseconds.
Each read replica has its Kubernetes deployment running multiple PgBouncer pods. Multiple deployments sit behind a single Kubernetes Service that load-balances traffic across pods. OpenAI co-locates the proxy, application clients, and database replicas in the same geographic region to minimize network latency and connection overhead.
See the diagram below: