|
npx workos: An AI Agent That Writes Auth Directly Into Your Codebase (Sponsored)
 |
npx workos launches an AI agent, powered by Claude, that reads your project, detects your framework, and writes a complete auth integration directly into your existing codebase. It’s not a template generator. It reads your code, understands your stack, and writes an integration that fits.
The WorkOS agent then typechecks and builds, feeding any errors back to itself to fix.
In December 2024, DeepSeek released V3 with the claim that they had trained a frontier-class model for $5.576 million. They used an attention mechanism called Multi-Head Latent Attention that slashed memory usage. An expert routing strategy avoided the usual performance penalty. Aggressive FP8 training cuts costs further.
Within months, Moonshot AI’s Kimi K2 team openly adopted DeepSeek’s architecture as their starting point, scaled it to a trillion parameters, invented a new optimizer to solve a training stability challenge that emerged at that scale, and competed with it across major benchmarks.
Then, in February 2026, Zhipu AI’s GLM-5 integrated DeepSeek’s sparse attention mechanism into their own design while contributing a novel reinforcement learning framework.
This is how the open-weight ecosystem actually works: teams build on each other’s innovations in public, and the pace of progress compounds. To understand why, you need to look at the architecture.
In this article, we will cover various open-source models and the engineering bets that define each one.
The Common Skeleton
Every major open-weight LLM released at the frontier in 2025 and 2026 uses a Mixture-of-Experts (MoE) transformer architecture.
See the diagram below that shows the concept of the MoE architecture:
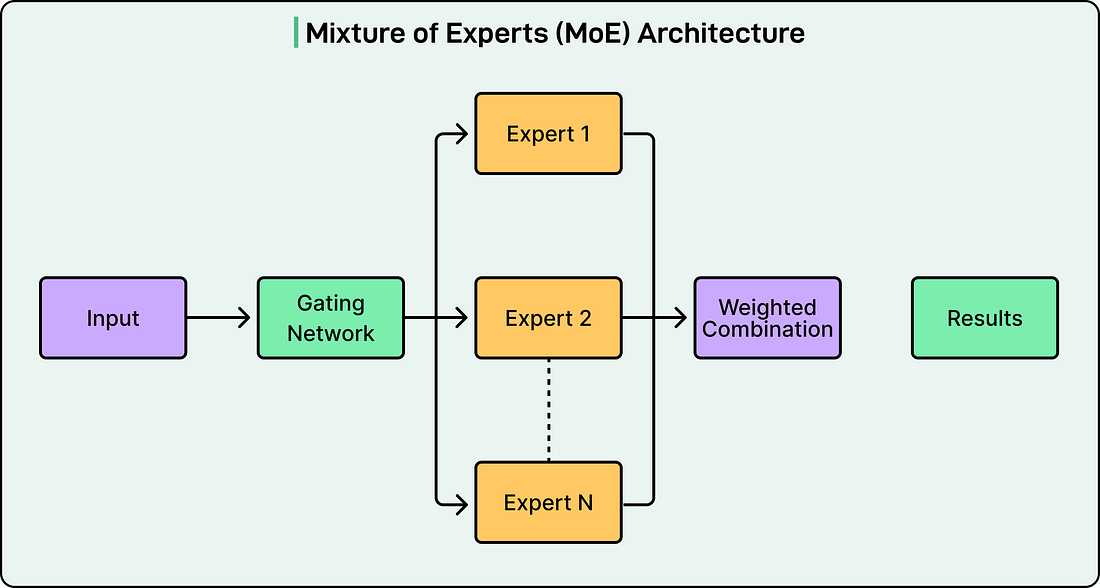 |
The reason is that dense transformers activate all parameters for every token. To make a denser model smarter, if you add more parameters, the computational cost scales linearly. With hundreds of billions of parameters, this becomes prohibitive.
MoE solves this by replacing the monolithic feed-forward layer in each transformer block with multiple smaller “expert” networks and a learned router that decides which experts handle each token. This result is a model that can, for example, store the knowledge of 671 billion parameters but only compute 37 billion per token.
This is why two numbers matter for every model:
Total parameters (memory footprint, knowledge capacity)
Active parameters (inference speed, per-token cost).
Think of a specialist hospital with 384 doctors on staff, but only 8 in the room for any given patient. You benefit from the knowledge of 384 specialists while only paying for 8 at a time. The triage nurse (the router) decides who gets called.
That’s also why a trillion-parameter model and a 235-billion-parameter model cost roughly the same per query. For example, Kimi K2 activates 32 billion parameters per token, while Qwen3 activates 22 billion. In other words, you’re comparing the active counts, not the totals.
Granola MCP (Sponsored)
 |
Take your meeting context to new places
If you’re already using Claude or ChatGPT for complex work, you know the drill: you feed it research docs, spreadsheets, project briefs... and then manually copy-paste meeting notes to give it the full picture.
What if your AI could just access your meeting context automatically?
Granola’s new Model Context Protocol (MCP) integration connects your meeting notes to your AI app of choice.
Ask Claude to review last week’s client meetings and update your CRM. Have ChatGPT extract tasks from multiple conversations and organize them in Linear. Turn meeting insights into automated workflows without missing a beat.
Perfect for engineers, PMs, and operators who want their AI to actually understand their work.
-> Try the MCP integration for free here or use the code BYTEBYTEGO