|
How AgentField Ships Production Code with 200 Autonomous Agents (Sponsored)
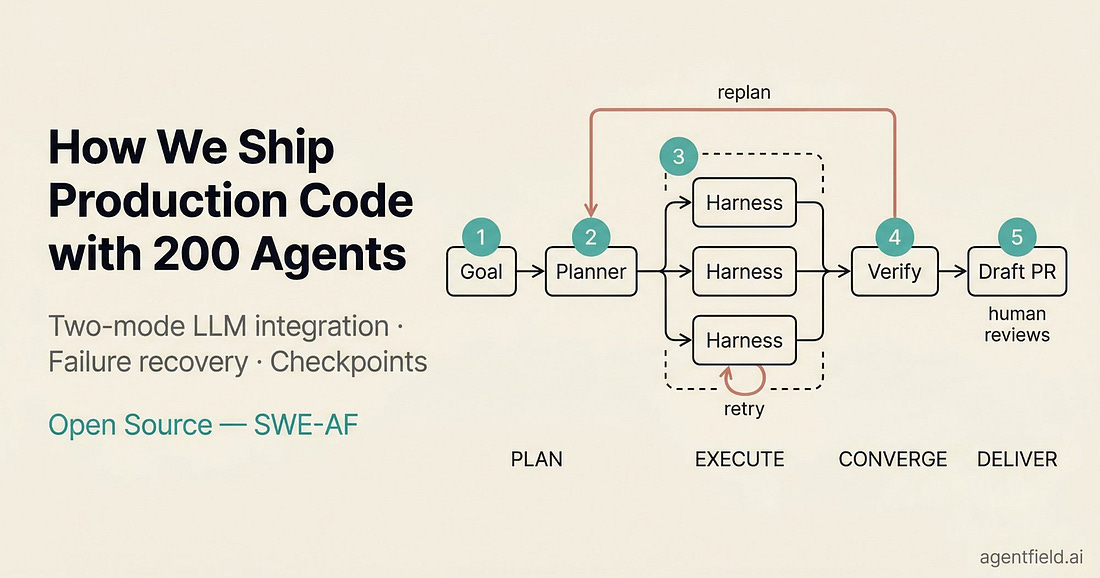 |
We hit the ceiling of single-session AI coding fast. We now orchestrate 200+ Claude Code instances in parallel on a shared codebase. Each instance runs in its own git worktree with filesystem access, test execution, and git. The system produces draft pull requests that have already been through automated writing, testing, code review, and verification before a human reviews them.
We recently open-sourced this system as SWE-AF. In this article, we cover the two-mode LLM integration pattern, a three-loop failure recovery hierarchy, and checkpoint-based execution that makes $116 builds survivable.
Nobody at Anthropic programmed Claude to think a certain way. They trained it on data, and it developed its own strategies, buried inside billions of computations. For the people who built it, this could feel like an uncomfortable black box. Therefore, they decided to build something like a microscope for AI, a set of tools that would let them trace the actual computational steps Claude takes when it produces an answer.
The findings surprised them.
Take a simple example. Ask Claude to add 36 and 59, and it will probably tell you it carried the ones and added the columns as per the standard algorithm we all learned in school. However, when the researchers watched what actually happened inside Claude during that calculation, they saw something quite different. There was no carrying. Instead, two parallel strategies ran at once, one estimating the rough answer and another precisely calculating the last digit. In other words, Claude got the math right, but had no idea how it was done.
That gap between what Claude says and what it actually does turned out to be just the beginning. Over the course of multiple research papers published in 2025, Anthropic’s interpretability team traced Claude’s internal computations across a range of tasks, from writing poetry to answering factual questions to handling dangerous prompts.
In this article, we will look at what the Claude researchers found.
Disclaimer: This post is based on publicly shared details from the Anthropic Research and Engineering Team. Please comment if you notice any inaccuracies.
Looking Inside an LLM
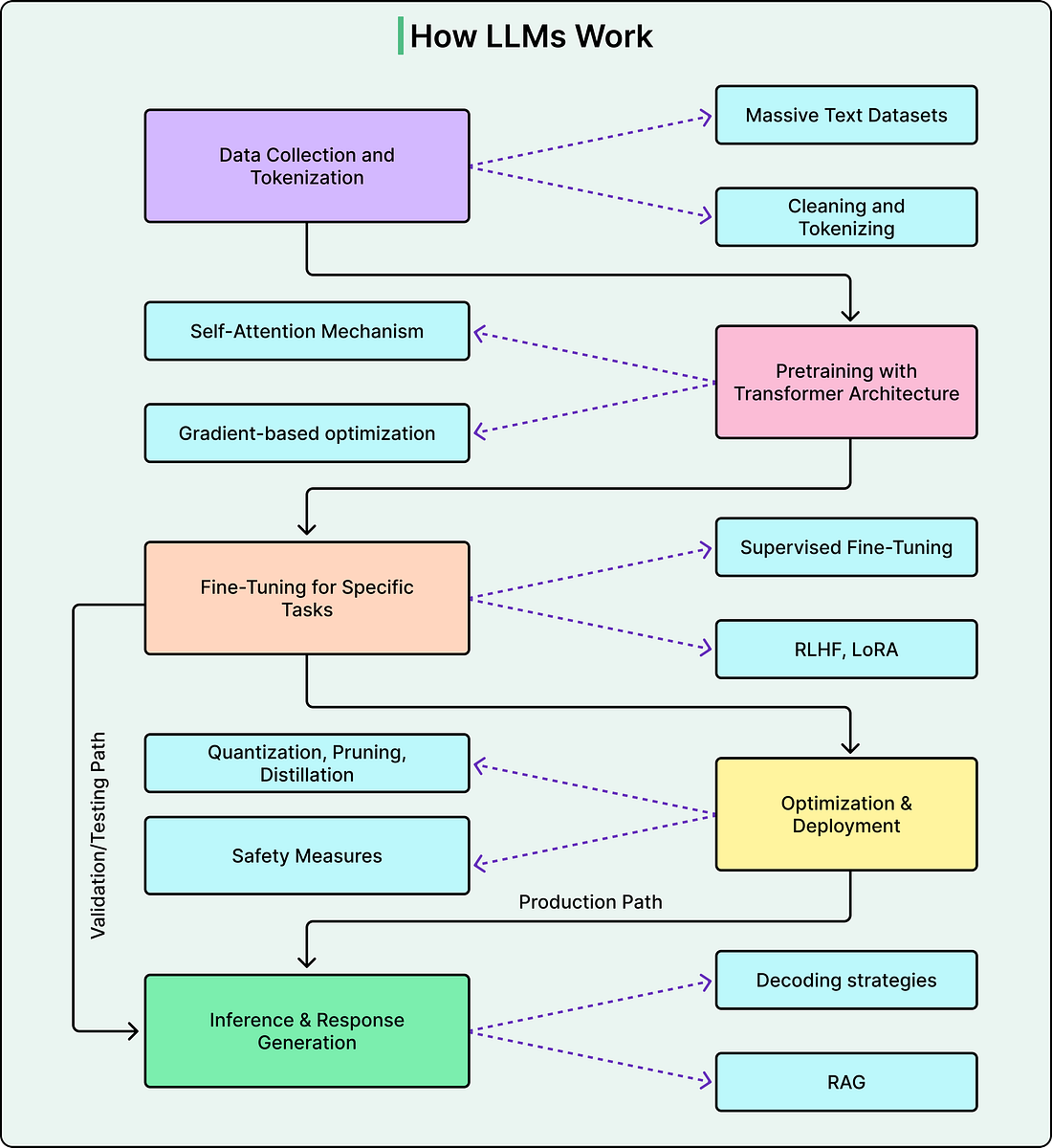
The diagram below shows a typical flow of how a modern LLM works:
 |
Before getting to the findings that Anthropic’s research team found, it helps to understand what this “microscope” actually is.
The core problem is that individual neurons inside an LLM’s neural network don’t map neatly to single concepts. One neuron might activate for “basketball,” “round objects,” and “the color orange” all at once. This is called polysemanticity, and it means that looking at neurons directly doesn’t tell us much about what the model is doing.
Anthropic’s solution is to use specialized techniques to decompose neural activity into what they call “features.” These are more interpretable units that correspond to recognizable concepts, such as things like smallness, known entity, or rhyming words.
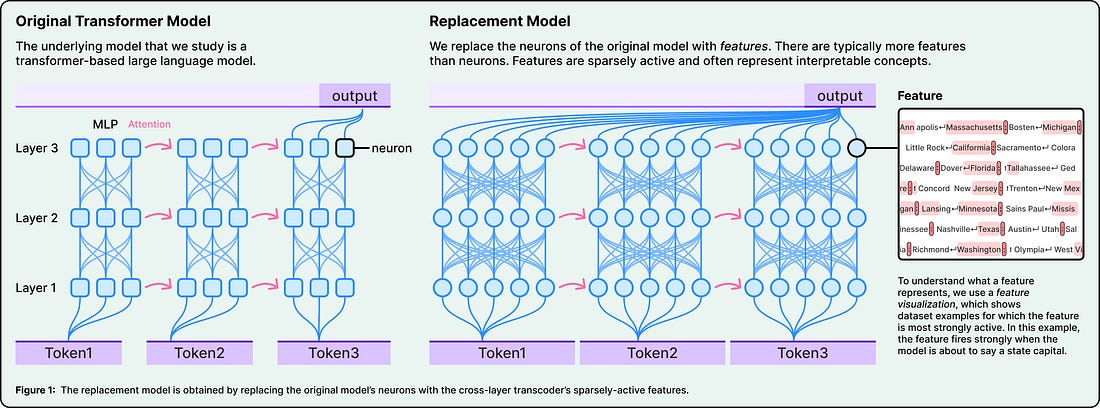
To find these features, the team built a replacement model, which is basically a simplified copy of Claude that swaps neurons for features while producing the same outputs. They study this copy, not Claude directly.
 |
Once they have features, they can trace how they connect to each other from input to output, producing attribution graphs. Think of these as wiring diagrams for a specific computation. And the most powerful part of this tool is the ability to intervene. You can reach into the model and suppress or inject specific features, then watch how the output changes. If you suppress the concept of “rabbit” and the model writes a different word, that’s strong causal evidence that the “rabbit” feature was doing what you thought it was doing. This technique is borrowed directly from neuroscience, where researchers stimulate specific brain regions to test their function.
Claude Thinks In Concept
Claude speaks dozens of languages fluently. So a natural question is whether there’s a separate “French Claude” and “English Claude” running internally, each responding in its own language.
There isn’t. When the researchers asked Claude for “the opposite of small” in English or French, they found that the same core features for “smallness” and “oppositeness” were activated regardless of the language used in the prompt. These shared features triggered a concept of “largeness,” which then got translated into whatever language the question was asked in.