|
The workshop for teams drowning in observability tools (Sponsored)
 |
Five vendors, rising costs, and you still can’t tell why something broke.
Sentry’s Lazar Nikolov sits down with Recurly’s Chris Barton to talk through what observability consolidation actually looks like in practice: how to evaluate your options, where AI fits in, and how to think about cost when you’re ready to simplify.
Giving an LLM more information can make it dumber. A 2025 research study by Chroma tested 18 of the most powerful language models available, including GPT-4.1, Claude, and Gemini, and found that every single one performed worse as the amount of input grew.
The degradation wasn’t minor, either. Some models held steady at 95% accuracy and then nosedived to 60% once the input crossed a certain length.
This finding busts one of the most common myths about working with LLMs that more context is always better. The reality is that LLMs have architectural blind spots that make what you put in front of them, and how you structure it, far more important than how much you include.
The discipline of getting this right is called context engineering.
In this article, we’ll look at how LLMs actually process the information you give them, what context engineering is, and the strategies that can help with it.
Key Terminologies
Before we go further, there are three terms that come up constantly when talking about LLMs. Getting clear on these first will make everything that follows much easier to reason about.
Tokens: They are the units LLMs think in. They aren’t full words, but rather chunks of text that average roughly three-quarters of a word each. The word “context” is one token, while the word “engineering” gets split into two. Every piece of text the model processes, from your question to its instructions to any documents you’ve included, is measured in tokens.
Context Window: It is the total number of tokens the model can see at once during a single interaction. Everything has to fit inside this window: the system instructions that define the model’s behavior, the conversation history, any external documents or data you’ve injected, and your actual question. Modern models advertise context windows ranging from 128,000 to over 2 million tokens. That sounds enormous, but as we’ll see, bigger isn’t straightforwardly better.
Attention: This is the mechanism the model uses to figure out which tokens matter to which other tokens. Before generating each new token of its response, the model compares it against every other token currently in the context window. This gives LLMs their ability to connect ideas across long stretches of text, but it’s also the source of their most important limitations.
How LLMs Process Context
When we send text to an LLM, it doesn’t read from top to bottom the way a human would. The attention mechanism compares every token against every other token to compute relationships, which means the model can, in principle, connect an idea from the first sentence of the input to one in the last sentence. However, this power comes with two critical costs.
The first is computational. Doubling the number of tokens in the context window roughly quadruples the computation required. Longer contexts are disproportionally slower and more expensive.
The second cost is more consequential. Attention isn’t distributed evenly across the context window. Research has consistently shown that LLMs pay the most attention to tokens at the beginning and end of the input, with a significant drop-off in the middle. This is known as the “lost in the middle” problem, and research has found that accuracy can drop by over 30% when relevant information is placed in the middle of the input compared to the beginning or end.
See the diagram below that shows the attention curve:
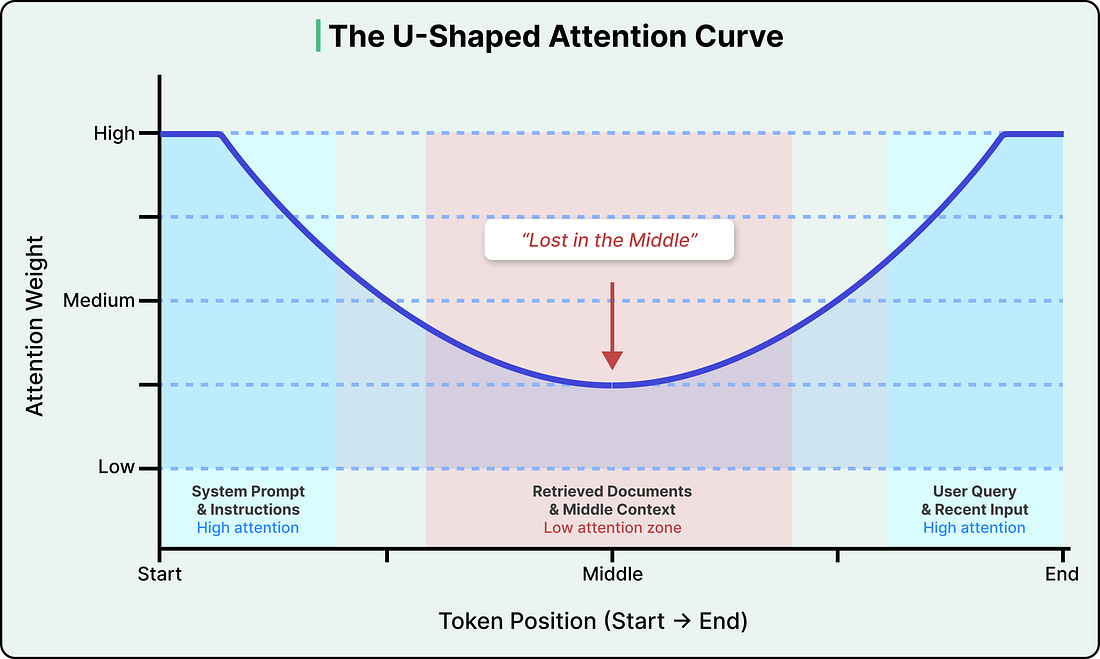 |
This isn’t a bug in any particular model, but rather a structural property of how transformers (the neural network architecture that powers virtually all modern LLMs) encode the position of tokens.
The positional encoding method used in most modern LLMs (called Rotary Position Embedding, or RoPE) introduces a decay effect that makes tokens far from both the start and end of the sequence land in a low-attention zone. Newer models have reduced the severity, but no production model has fully eliminated it.
The practical implication is that the position of information in the input matters as much as the information itself. If we paste a long document into an LLM, the model is most likely to miss information buried in the middle pages.
Why More Context Can Hurt
The uneven attention distribution is one problem, but there’s a broader pattern that compounds it, known as context rot.
Context rot is the degradation of LLM performance as input length increases, even on simple tasks. The Chroma research team’s 2025 study tested 18 frontier models and found that this degradation isn’t gradual. Models can maintain near-perfect accuracy up to a certain context length, and then performance drops off a cliff unpredictably, varying by model and by task in ways that make it impossible to reliably predict when you’ll hit a breaking point.
Why does this happen?
Every token you add to the context window draws from a finite attention budget. Irrelevant information buries important information in low-attention zones, and content that sounds related but isn’t actually useful confuses the model’s ability to identify what’s relevant. The model doesn’t get smarter with more input, but kind of gets distracted.
On top of this, LLMs are stateless. They have zero memory between calls, and each interaction starts completely fresh. When there is a multi-turn conversation with an LLM like ChatGPT, and it seems to “remember” what we said earlier, that’s because the system is re-injecting the conversation history into the context window each time. The model itself remembers nothing, which means someone, or some system, has to decide for every single call what information to include, what to leave out, and how to structure it.