|
How to stop babysitting your agents (Sponsored)
 |
Agents can generate code. Getting it right for your system, team conventions, and past decisions is the hard part. You end up babysitting the agent and watch the token costs climb.
More MCPs, rules, and bigger context windows give agents access to information, but not understanding. The teams pulling ahead have a context engine to give agents only what they need for the task at hand.
Join us for a FREE webinar on April 23 to see:
Where teams get stuck on the AI maturity curve and why common fixes fall short
How a context engine solves for quality, efficiency, and cost
Live demo: the same coding task with and without a context engine
If you want to maximize the value you get from AI agents, this one is worth your time.
LinkedIn used to run five separate systems just to decide which posts to show you. One tracked trending content. Another did collaborative filtering. A third handled embedding-based retrieval.
Each had its own infrastructure, its dedicated team, and its own optimization logic. The setup worked, but when the Feed team wanted to improve one part, they’d break another. Therefore, they made a radical bet and ripped out all five systems, replacing them with a single LLM-powered retrieval model. That solved the complexity problem, but it raised new questions, such as:
How do you teach an LLM to understand structured profile data?
How do you make a transformer serve predictions in under 50 milliseconds for 1.3 billion users?
How do you train the model when most of the data is noise?
In this article, we will look at how the LinkedIn engineering team rebuilt the Feed and the challenges they faced.
Disclaimer: This post is based on publicly shared details from the LinkedIn Engineering Team. Please comment if you notice any inaccuracies.
Five Librarians, One Library
For years, LinkedIn’s Feed retrieval relied on what engineers call a heterogeneous architecture. When you opened the Feed, content came from multiple specialized sources running in parallel.
A chronological index of network activity.
Trending posts by geography.
Collaborative filtering based on similar members.
Industry-specific pipelines.
Several embedding-based retrieval systems.
Each maintained its own infrastructure, index structure, and optimization strategy.
See the diagram below:
 |
This architecture surfaced diverse, relevant content. But optimizing one retrieval source could degrade another, and no team could tune across all sources simultaneously. Holistic improvement was nearly impossible.
So the Feed team asked a simple question. What if they replaced all of these sources with a single system powered by LLM-generated embeddings?
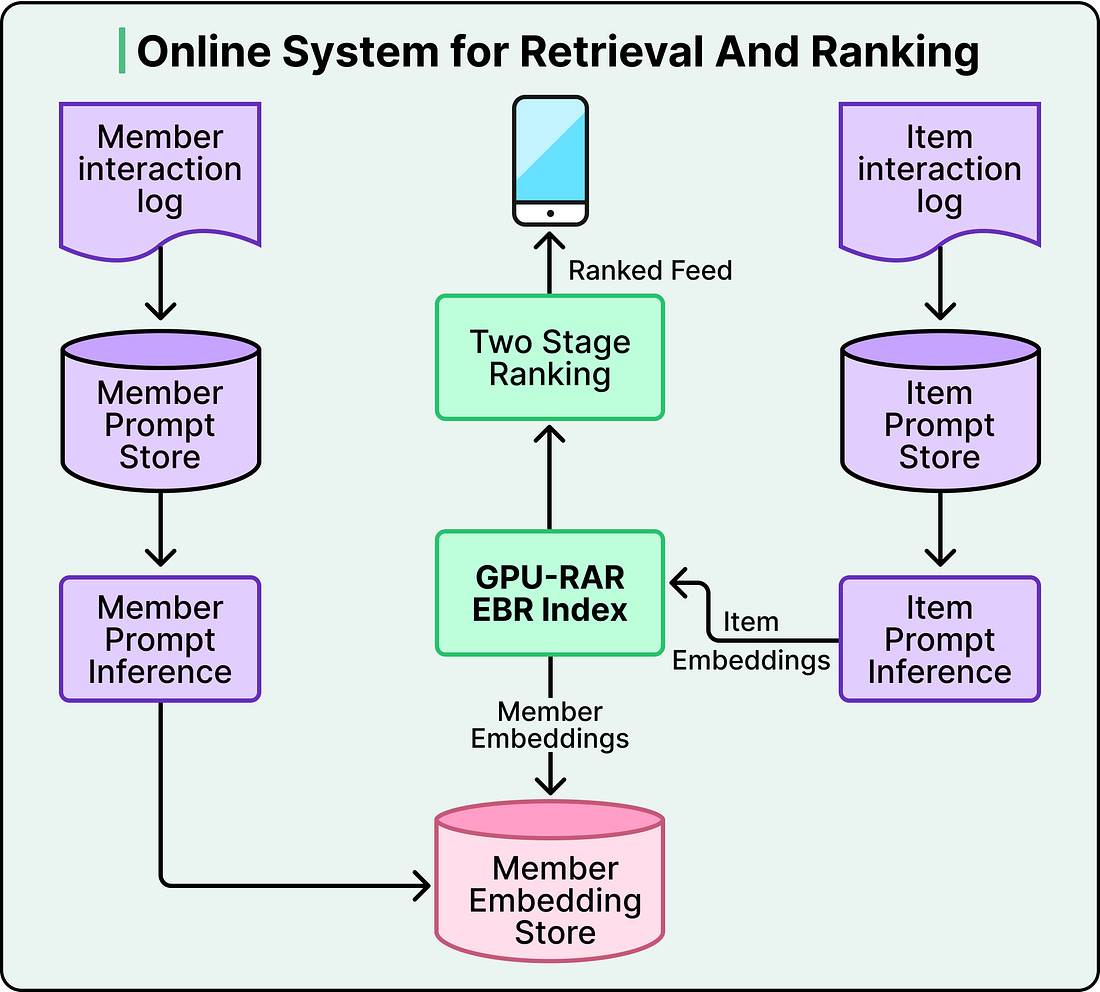
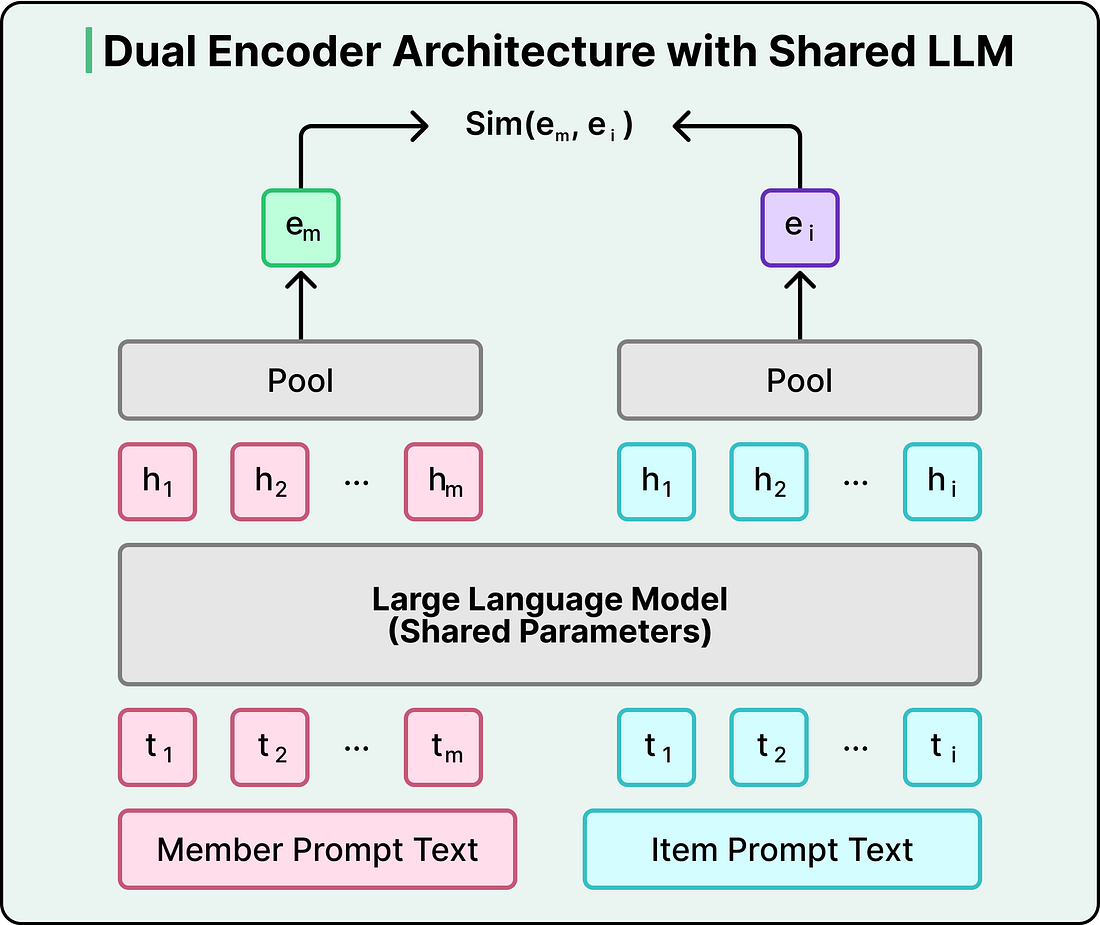
Under the hood, this works through a dual encoder architecture. A shared LLM converts both members and posts into vectors in the same mathematical space. The training process pushes member and post representations close together when there’s genuine engagement, and pulls them apart when there isn’t. When you open your Feed, the system fetches your member embedding and runs a nearest-neighbor search against an index of post embeddings, retrieving the most relevant candidates in under 50 milliseconds.
 |
However, the real power comes from what the LLM brings to those embeddings. Traditional keyword-based systems rely on surface-level text overlap. If your profile says “electrical engineering” and a post is about “small modular reactors,” a keyword system misses the connection.
An LLM-based system understands that these topics are related because the model carries world knowledge from pretraining. It knows that electrical engineers often work on power grid optimization and nuclear infrastructure. This is especially powerful for cold-start scenarios, when a new member joins with just a profile headline. The LLM can infer likely interests without waiting for engagement history to accumulate.
The downstream benefits compounded the benefits. Instead of receiving candidates from disparate sources with different biases, the ranking layer now receives a coherent candidate set selected through the same semantic similarity. Ranking became easier, and each optimization to the ranking model became more effective.
But replacing five systems with one LLM created a new problem. LLMs expect text, and recommendation systems run on structured data and numbers.