|
Your agent isn’t broken. Your context is. (Sponsored)
 |
Most AI agents don’t fail because the model is bad. They fail because the model doesn’t have the proper infrastructure to reason well.
Simba Khadder, Head of Engineering at Redis, lays out a 4 pillar framework for building context systems that hold up in production—plus an architectural self-audit checklist you can run against your stack today.
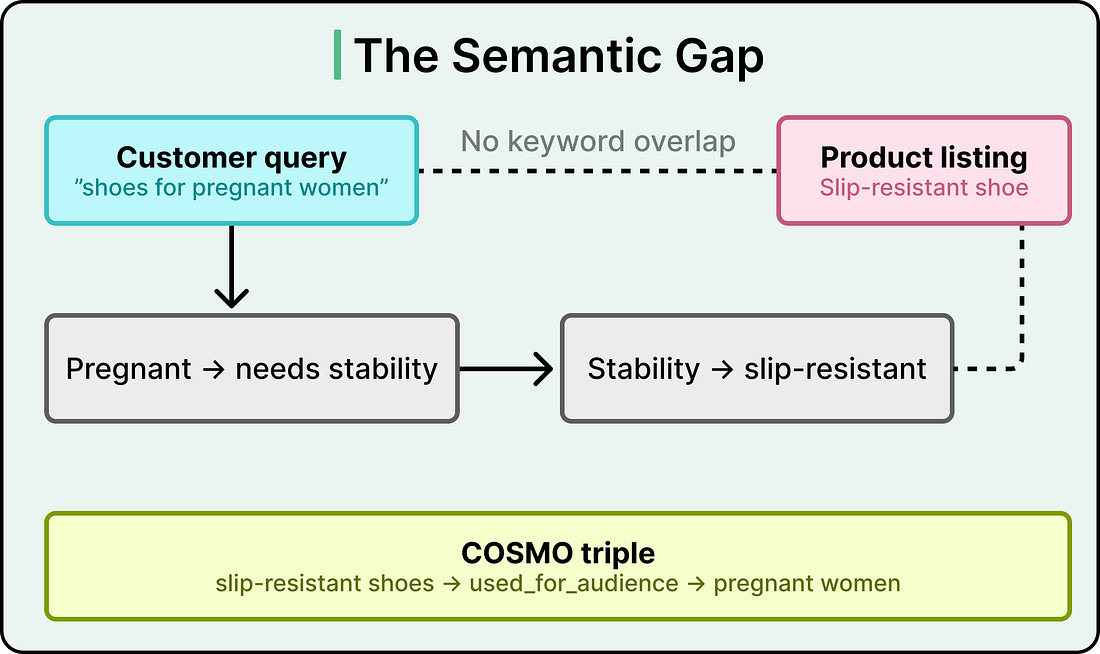
Search “shoes for pregnant women” on Amazon, and the best results you get might be slip-resistant shoes. This is even though the word “pregnant” appears nowhere in those product listings.
In other words, there is zero keyword overlap between the query and the product. The search engine has to reason that pregnant women need stability, that stability means slip-resistance, and that slip-resistant shoes are the right match.
Traditional recommendation systems match text to text and purchase history to purchase history. They handle keyword overlap quite well. However, when a shopper’s intent requires a reasoning step that lives entirely in human common sense, those systems hit a wall.
Amazon’s search team recognized this blind spot and built a commonsense knowledge graph called COSMO that teaches the recommendation engine to think the way a human shopper would.
In this article, we will look at how COSMO works and the challenges the engineering team faced.
Disclaimer: This post is based on publicly shared details from the Amazon Engineering Team. Please comment if you notice any inaccuracies.
The Gap Between What You Search and What You Mean
Amazon already operates large-scale knowledge graphs that store factual product attributes like brand, color, material, and category. These graphs power a lot of what works well in product search today. However, they mainly try to encode what a product is, and they don’t explain why a human would want it.
This is the semantic gap problem.
For example, a query like “winter clothes” carries an implicit intent around warmth. The product catalog for a long-sleeve puffer coat describes its material, size options, and sleeve length, but it may say nothing about warmth directly. The gap between what the customer typed and what the product listing says requires a reasoning step that factual knowledge graphs were never designed to handle.
 |
Amazon’s team surveyed the landscape of existing solutions.
Alibaba built AliCoCo (163K nodes, 91 relations) and AliCG (5M nodes), both extracted from search logs. These capture product concepts, but they stay focused on product attributes and categories, skipping user intent entirely.
General commonsense knowledge bases like ConceptNet (8M nodes, 21M edges) cover everyday reasoning but are built for general purposes, with little grounding in shopping behavior.
Amazon’s own earlier effort, FolkScope, demonstrated that commonsense knowledge could be extracted from shopping data, but it covered only 2 product categories and only co-purchase behavior.
The gap was clear. Though factual product knowledge and general commonsense knowledge existed, structured knowledge about why people buy things at an e-commerce scale was missing.
Asking the LLM (and Why the Answers Fell Short)
The intuition behind Amazon’s approach was simple. Large language models encode enormous amounts of world knowledge in their parameters. Taking our earlier example, if you ask an LLM why a customer who searched “winter coat” bought a long-sleeve puffer coat, it can reason that puffer coats provide warmth, and warmth is what the customer wanted.
The team fed millions of user behavior pairs into OPT-175B and OPT-30B, large language models hosted internally on 16 A100 GPUs. The choice of OPT over GPT-4 was driven by a hard constraint around data privacy. Customer behavior data, meaning which queries led to which purchases, could only be processed on Amazon’s own infrastructure.
Two types of behavior data went into the system.
Query-purchase pairs capture the connection between a search query and the product a customer ultimately bought.
Co-purchase pairs capture products bought together in the same shopping session
Across 18 product categories, the team sampled 3.14 million co-purchase pairs and 1.87 million query-purchase pairs.
The sampling strategy was itself a design decision.
For products, Amazon covered popular browse node categories and selected top-tier products with high interaction volume, also using product type labels (more than a thousand classes like “umbrella” or “chair”) for finer-grained selection.
For co-purchase pairs, the team cross-checked product types to remove random co-purchases and filtered out products that co-occurred with too many different product types (a signal of noise rather than intent).
For search-buy pairs, thresholds on both purchase rate and click rate determined which queries and products entered the sample.
Crucially, an in-house query specificity service helped prioritize broad or ambiguous queries, because those are exactly where the semantic gap is largest and commonsense knowledge adds the most value.
Prompt design mattered too. Rather than using simple text continuation, Amazon formatted each behavior pair as a question-answering task and instructed the LLM to generate a numbered list of candidates rather than a single response.
The LLM generated millions of candidate explanations. However, only 35% of search-buy explanations met Amazon’s quality bar for typicality, meaning they were representative of genuine shopping intent. For co-purchase explanations, that number dropped to 9%. The rest were filler. The LLM produced circular rationales like “customers bought them together because they like them,” or trivially obvious statements like “customers bought an Apple Watch because it is a type of watch.”
The 9% vs. 35% gap reveals something about how LLMs reason. Explaining why a query led to a purchase is relatively constrained because the query provides clear context about intent. But explaining why two products were bought together requires identifying a shared reason across two different items, and LLMs tend to default to generic explanations for one item rather than reasoning about the pair.