|
GitLab Transcend is next week. Built for engineers. Free to attend. Don’t miss it. (Sponsored)
 |
New research. New announcements. A new chapter for GitLab.
On June 10, GitLab Transcend streams live from London — and engineers get a first look at GitLab 19 and Duo Agent Platform advancements before anyone else.
Including a live demo of GitLab Orbit: a knowledge graph across your entire SDLC so your agents know your pipelines, your security backlog, and what shipped last week. Not just your repo.
Virtual, free, and just days away.
OpenAI’s data platform stores 1.5 exabytes across 90,000 datasets and serves ~4,000 internal users as of May 2026. The team has scaled the platform through enormous growth in the last two years. At this scale, the hardest part of data analysis isn’t writing SQL. It’s finding the right tables to use in the first place and understanding semantically how to use data. Many tables look similar but mean different things. What’s the grain of each table? How do you join them against other data? Analysts can spend hours figuring out which tables to use and how to use them before writing a single line of code.
Last year, OpenAI’s data platform team built an in-house agent to fix that. The agent is, in their own words, “pretty vanilla”, yet it works reliably across the entire ecosystem. And the same investment in Codex that powers the agent has let the team do things most companies consider impossible, like migrating thousands of DAGs, 90,000 tables and 600 petabytes between clouds in two months.
We spoke with Emma Tang, Head of Data Platform Engineering at OpenAI, about how the agent works, why a simple architecture is enough at this scale due to strong data infrastructure foundations, the lessons for other teams, and where the platform is headed next. Thanks to Emma for taking the time to share the team’s work in detail.
In this article, you’ll learn:
The architecture behind OpenAI’s data agent, and why “vanilla” is the point.
The six layers of context that turn a single LLM into a reliable analyst across 90,000 tables.
How a question becomes a verified answer in three steps.
Three real Codex use cases inside OpenAI: a 10,000 DAG, 90,000-table cross-cloud migration, hands-off open-source patching, and automated support triage.
Five practical lessons for any team building a domain agent, and where OpenAI’s data platform is headed next.
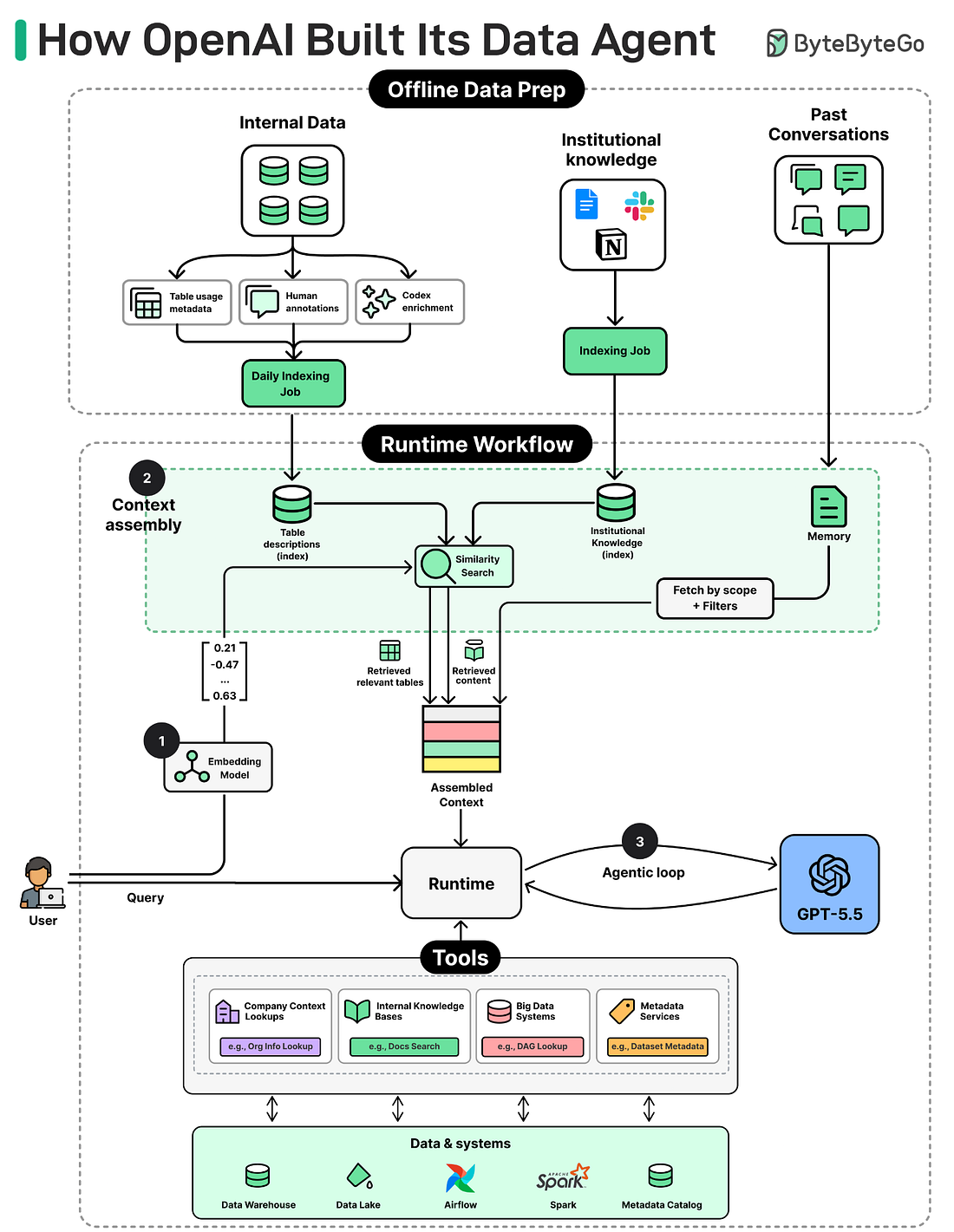 |
How the Data Agent Works
To understand the agent, we will look at three things: what users experience when they ask a question, what architecture supports that experience, and how a request moves through the agent until it returns a verified answer.
The User Experience: Ask in Plain English
Imagine an engineer or marketer at OpenAI who needs a quick answer. They open Slack and ask their questions in plain English. Moments later, the agent replies with its answer, the SQL it ran, and the tables it pulled from. That’s OpenAI’s data agent.
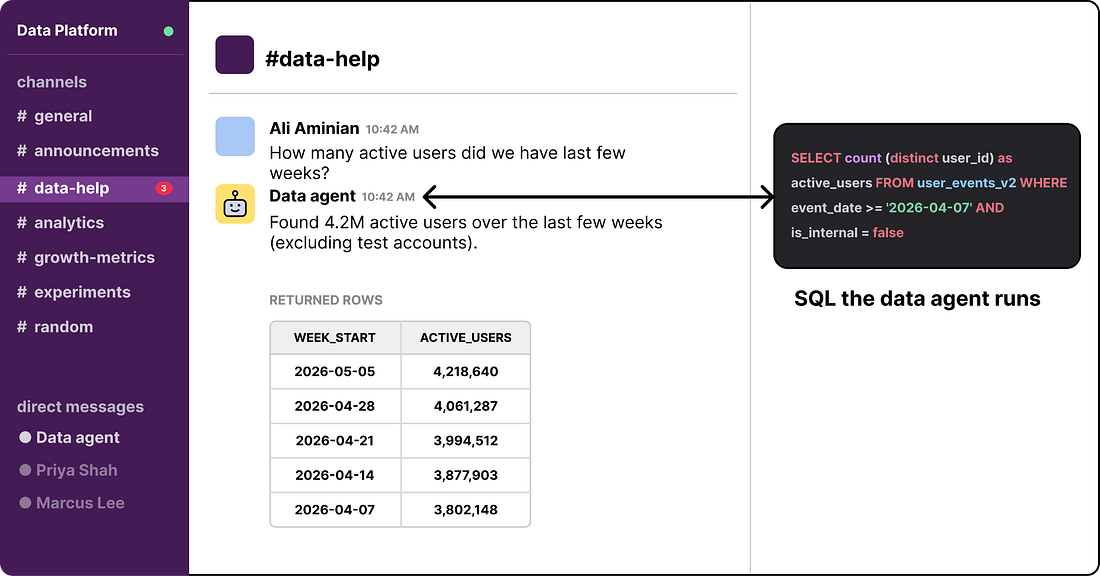 |
The agent sits across the entire data platform and answers questions in natural language. A user can ask in Slack, in a web portal, in their IDE, or in the Codex CLI through MCP. The agent figures out which tables are relevant, writes SQL, runs it, checks the result, and returns the answer with its reasoning attached.
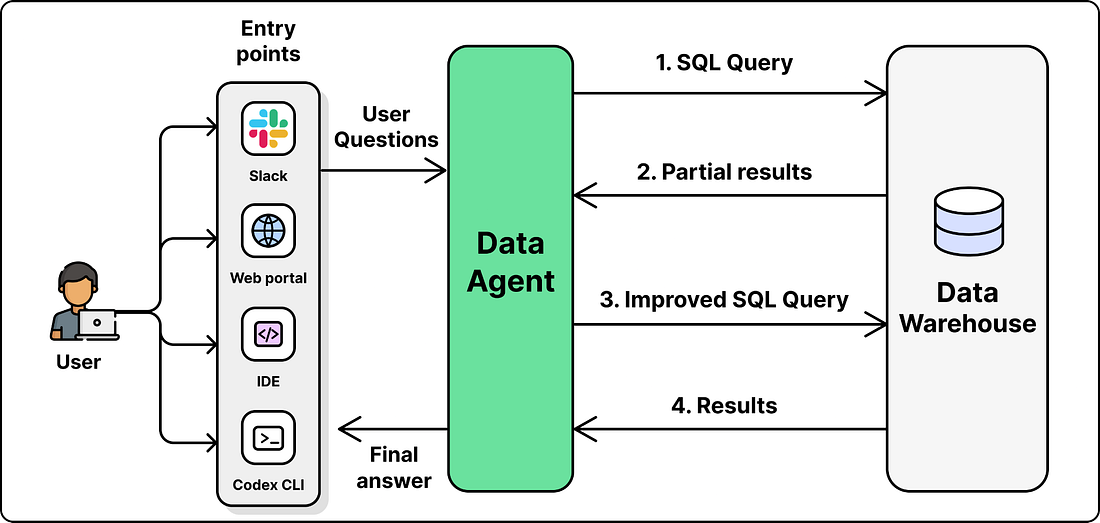 |
Doing all of this reliably across 90,000 tables sounds like it would need a complex system. The team’s approach is the opposite of what most people expect. The agent itself is simple. The reliability comes from the engineering around it: careful data acquisition that gives the agent the right context before it ever sees a question. The next sections look at how th