|
FeatureOps Summit 2026 - Feature management in the AI Era (Sponsored)
 |
Speed without control is a false economy. As AI code-generation accelerates software delivery, the FeatureOps Summit 2026 is here to ensure that when we ship more, we break less.This premier virtual event brings together engineers, architects, and product leaders from companies like Wayfair, Visa, Mintlify, Lloyds, and many others, to explore the infrastructure of fearless delivery.
Key Themes:
AI Safety Nets: Guardrails for the flood of automated code.
Edge Resilience: Sub-millisecond evaluation at scale.
Continuous Flow: Moving past the “fixed-release” mindset. Register today to master the tools and patterns required for a fail-safe release environment.
Every time an LLM generates a response, two operations run in sequence on the same GPU. The first processes the input prompt and emits a single token. The second produces every token after that, one at a time.
From the outside, they look like stages of one process. However, inside the hardware, they have opposite bottlenecks. One is limited by raw compute. The other is limited by how fast data moves through memory. Most of the engineering work that makes production AI systems fast exists because of this split, and the techniques used to handle it are what inference engineering is built around.
Inference engineering is the discipline of running trained AI models in production efficiently. The work spans low-level GPU code, model serving frameworks, and the cloud infrastructure that ties them together. Engineers in this field optimize for some combination of latency, throughput, cost, and quality, with the specific mix depending on the product they support. A few years ago, this work happened almost entirely inside frontier AI labs. Today, it has become a broad specialty that any company running serious AI workloads invests in.
In this article, we will walk through how inference works and why the field’s optimization techniques exist.
Disclaimer: This post is based on publicly shared details from various sources. Please comment if you notice any inaccuracies.
The Rise of Inference Engineering
Three years ago, inference engineering was a specialty practiced almost entirely inside frontier AI labs. The work concerned a small group of engineers building closed models that the rest of the industry consumed through APIs. That picture has shifted dramatically since 2024.
Open models drove the change. Hugging Face, the public registry for AI models, now hosts well over two million open models, roughly 25 times what existed five years ago. Open releases like DeepSeek V3 have closed the capability gap with closed models, giving companies a real choice between paying for a closed API and running an open model themselves.
Self-hosting open models brings three operational advantages over closed APIs:
Latency profiles can be tuned for the workload pattern of a specific product, where public APIs optimize for general throughput across many customers.
Uptime can reach four nines or better with dedicated deployments, comparing favorably to the two nines typical of public APIs.
Costs typically drop by around 80 percent at scale once volume justifies the engineering investment.
The result is that companies across many categories now build serious inference stacks, including AI-native startups, established products integrating AI into existing workflows, and even traditionally cautious sectors like healthcare.
Cursor offers a representative example. The team built Composer 2.0 on top of an open model, applying extensive inference engineering to deliver autocomplete latency below what closed APIs offer.
The Two Phases of LLM inference
Understanding why inference engineering looks the way it does starts with understanding what actually happens when a prompt arrives at an LLM. The process splits into two phases with very different physical demands on the GPU.
A token is the atomic unit that an LLM works with. Roughly, it is a word or word fragment. The word “inference” might be one token, while “engineering” might break into two. Latency metrics that mention tokens per second are counted in this unit.
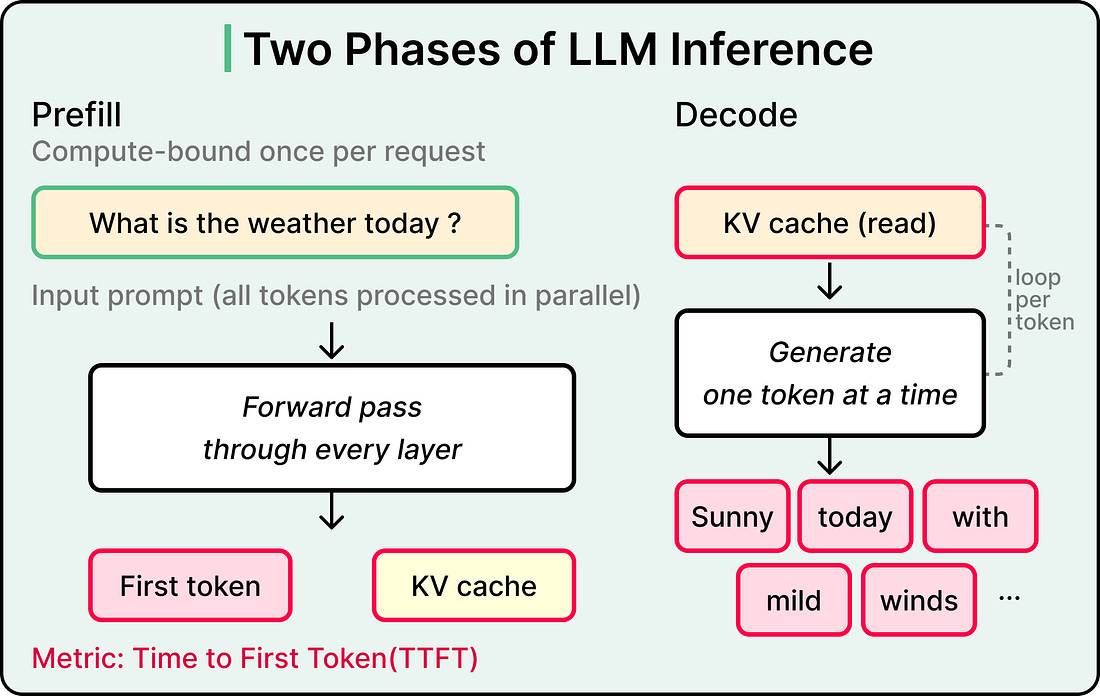
The first phase is called prefill.
The model takes the entire input prompt and runs it through every layer of weights in parallel. Two outputs come out of this burst, namely the first token of the response and the KV cache, which is a structure that stores intermediate values from the attention mechanism so they can be referenced as more tokens get generated.
Prefill is compute-bound. The GPU’s math units are the limiting factor because every input token gets processed simultaneously through every layer of the model, and throwing more raw computational power at this phase makes it faster. The metric that captures prefill performance is time to first token, or TTFT. That brief pause between sending a prompt to ChatGPT and seeing the first tokens appear is prefill in action.
The second phase is the decode phase. The model generates each subsequent token one at a time, running a full forward pass through every layer of weights for every token. Each new token depends on every token before it, which makes the process fundamentally sequential, and the GPU does this thousands of times for a long response.
Decode is memory-bandwidth-bound. Math throughput sits mostly idle while the GPU spends its cycles reading model weights from memory for each forward pass, with the bottleneck living in data movement rather than arithmetic. The metric that captures decode performance is tokens per second, or TPS. The streaming pace of a long response is the decode phase at work.
 |
Since prefill and decode have opposite bottlenecks, a technique that accelerates one phase often has minimal impact on the other. This is why benchmarks report TTFT and TPS as separate numbers, with performance on each phase measured independently.
This split is also the structural insight that organizes the rest of inference engineering. Once prefill and decode are understood as two distinct operations, the field’s techniques sort themselves into three groups: those that accelerate prefill, those that accelerate decode, and those that rebalance the two against each other.
The picture above is somewhat simplified. Real inference engines run batching, scheduling, and other complexity layered on top, and the prefill-decode split holds underneath all of it, which is why it serves as the foundation for the rest of this article.
Optimization Techniques
With the prefill-decode split in mind, the major tec