|
Turn cloud logs into real security signals (Sponsored)
This guide from Datadog provides best practices on how to use Cloud SIEM to detect threats, investigate incidents, and reduce blind spots across cloud and Kubernetes environments.
You’ll learn how to:
Analyze CloudTrail, GCP audit, and Azure logs for suspicious activity
Detect authentication anomalies and common attack patterns
Monitor Kubernetes audit logs for lateral movement and misuse
Correlate signals across services to accelerate investigations
This week’s system design refresher:
12 Claude Code Features Every Engineer Should Know
How Agentic RAG Works?
How does REST API work?
7 Key Load Balancer Use Cases
Our New Book on Behavioral Interviews Is Now Available on Amazon!
12 Claude Code Features Every Engineer Should Know
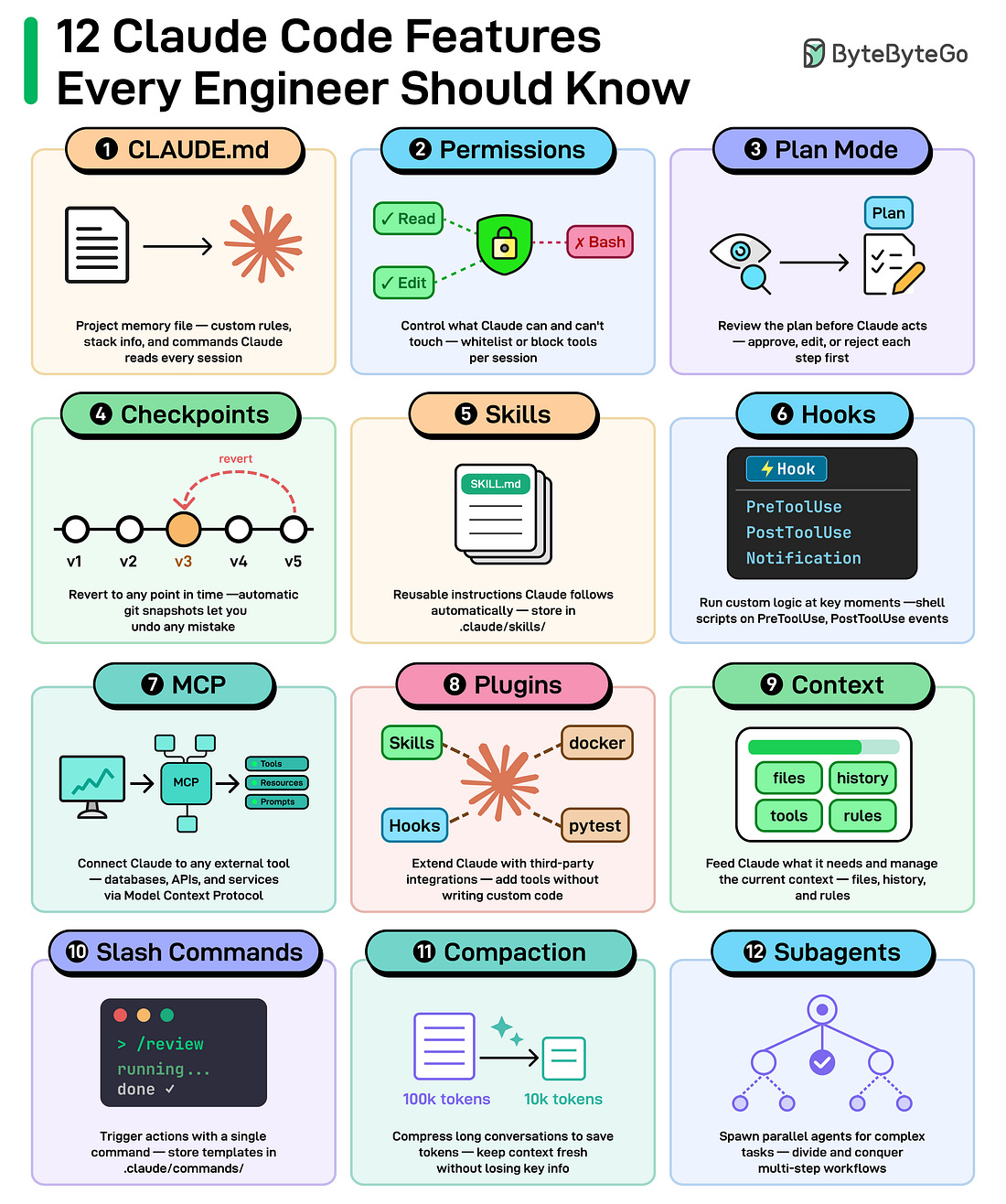 |
CLAUDE. md: A project memory file to define custom rules and conventions. Claude reads at the start of every session.
Permissions: Control which tools Claude can and can't use.
Plan Mode: Claude plans before it acts. You can review them before any code changes.
Checkpoints: Automatic snapshots of your project to revert to if something goes wrong.
Skills: Reusable instruction files Claude follows automatically.
Hooks: Run custom shell scripts on lifecycle events like PreToolUse or PostToolUse.
MCP: Connect Claude to any external tools like databases and third-party services.
Plugins: Extend Claude with third-party integrations containing skills, MCPs, and hooks.
Context: Feed Claude what it needs and manage the current context window with /context.
Slash Commands: Create shortcuts for tasks you run often. Type / and pick from your saved commands.
Compaction: Compress long conversations to save tokens.
Subagents: Spawn parallel agents for complex tasks. Divide large multi-step workflows and run them simultaneously.
Over to you: Which Claude Code feature do you use the most? Any features you wish were on this list?
How Agentic RAG Works?
 |
A traditional RAG has a simple retrieval, limited adaptability, and relies on static knowledge, making it less flexible for dynamic and real-time information.
Agentic RAG improves on this by introducing AI agents that can make decisions, select tools, and even refine queries for more accurate and flexible responses. Here’s how Agentic RAG works on a high level:
The user query is directed to an AI Agent for processing.
The agent uses short-term and long-term memory to track query context. It also formulates a retrieval strategy and selects appropriate tools for the job.
The data fetching process can use tools such as vector search, multiple agents, and MCP servers to gather relevant data from the knowledge base.
The agent then combines retrieved data with a query and system prompt. It passes this data to the LLM.